NVIDIA выпускает LocateAnything-3B — модель привязки визуального языка с открытым исходным кодом и параллельным декодированием боксов
NVIDIA открывает исходный код LocateAnything-3B, модели визуально-языковой привязки с Parallel Box Decoding (PBD) для быстрой и точной локализации объектов, поддерживающей обнаружение объектов, привязку элементов GUI, локализацию OCR и точечную привязку в различных областях
29 июня 2026 года компания NVIDIA официально выпустила LocateAnything-3B — модель визуально-языковой привязки с открытым исходным кодом, обеспечивающую быструю и качественную визуальную локализацию по командам на естественном языке. Модель представляет Parallel Box Decoding (PBD) — новый парадигма декодирования, которая предсказывает полные координаты ограничивающих прямоугольников за один параллельный шаг вместо авторегрессивного декодирования токен за токеном, достигая пропускной способности до 2.5× выше по сравнению с предыдущими подходами.
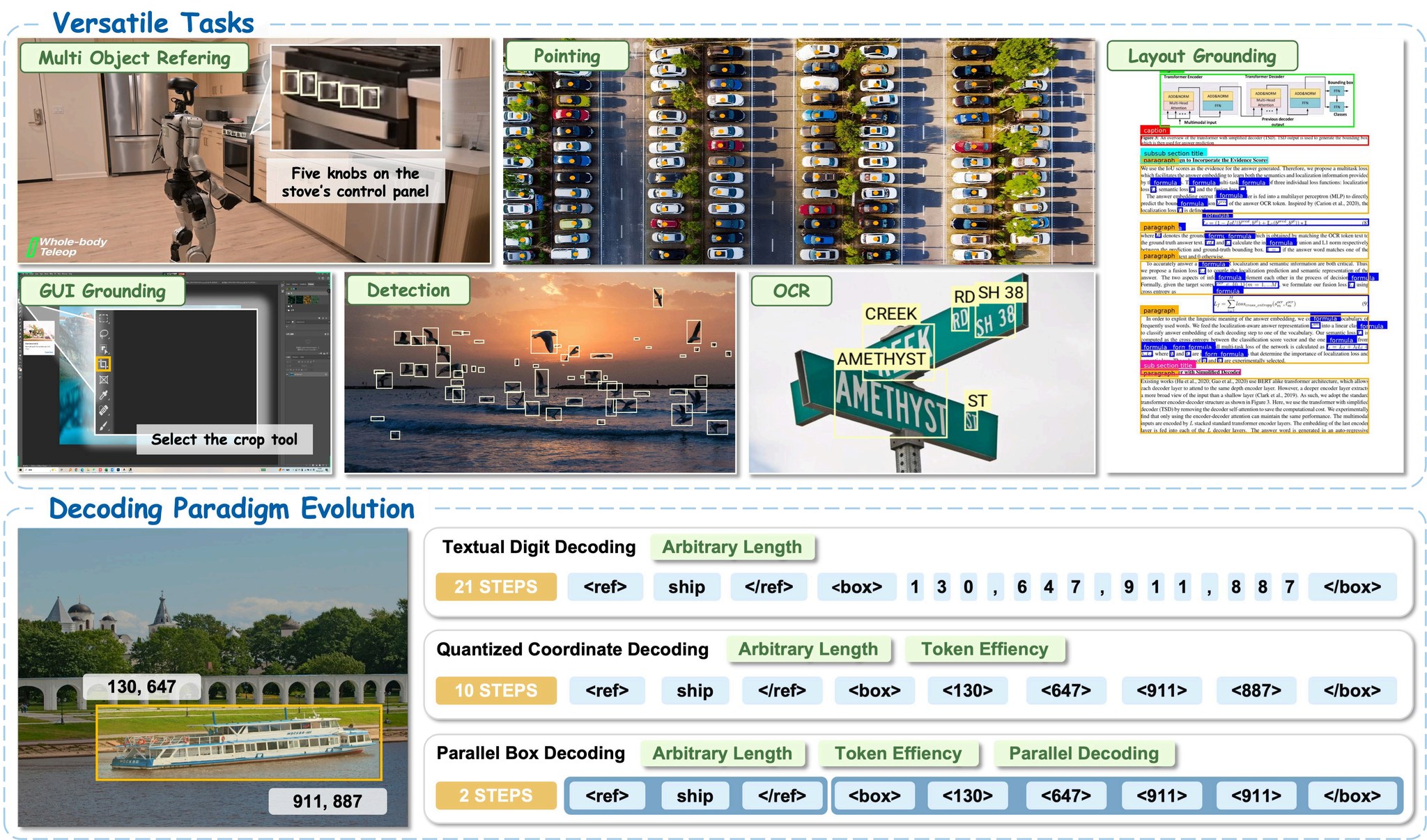 LocateAnything обеспечивает точную локализацию объектов в различных областях, включая природные сцены, робототехнику, взаимодействие с GUI и понимание документов.
LocateAnything обеспечивает точную локализацию объектов в различных областях, включая природные сцены, робототехнику, взаимодействие с GUI и понимание документов.
Обзор модели
LocateAnything — это универсальная модель визуально-языковой привязки, разработанная в рамках семейства моделей NVIDIA Eagle VLM. Она поддерживает широкий спектр задач локализации:
- Привязка по референтным выражениям: Локализация объектов, описанных на естественном языке
- Обнаружение объектов открытого множества: Детекция как обычных, так и редких категорий объектов
- Привязка элементов GUI: Локализация элементов пользовательского интерфейса для агентных систем
- Привязка макетов документов: OCR и локализация текста
- Точечная локализация: Тонкое пространственное рассуждение с помощью указания
Модель интегрирована в продуктовые линейки NVIDIA Nemotron и Cosmos, обеспечивая функции компьютерного использования и визуальной привязки.
Ключевая инновация: Parallel Box Decoding (PBD)
Традиционные модели визуальной привязки генерируют координаты ограничивающих прямоугольников авторегрессивно, токен за токеном. LocateAnything представляет Parallel Box Decoding:
- Предсказывает полные ограничивающие прямоугольники (
x1, y1, x2, y2) и точки в параллельных структурированных блоках - Использует блочную структуру предсказания нескольких токенов
- Достигает пропускной способности в 2.5× выше без потери геометрической согласованности
- Поддерживает три режима вывода:
- Быстрый режим: Параллельное декодирование для максимальной скорости
- Медленный режим: Авторегрессивное декодирование для максимальной точности
- Гибридный режим: По умолчанию; параллельное декодирование с возвратом к авторегрессивному при нарушениях формата
Техническая архитектура
| Компонент | Детали |
|---|---|
| Архитектура | Трансформерная VLM |
| Кодировщик изображений | MoonViT (нативное разрешение, до 2.5K) |
| Языковая модель | Qwen2.5-3B-Instruct |
| Мультимодальный проектор | MLP проектор |
| Всего параметров | 3B |
| Макс. разрешение изображения | 2.5K (продакшн), до 4K при батч-инференсе |
| Макс. длина последовательности | 25 600 токенов (обучение), 8192 токенов генерации (инференс) |
| Формат вывода | На основе блоков: Semantic, Box, Negative и End блоки |
Данные для обучения
- 12M уникальных изображений, 138M+ запросов, 785M ограничивающих прямоугольников
- Мультидоменные: природные сцены, робототехника, вождение, GUI, документы
- Гибридные источники данных: кураторские, открытые, синтетические аннотации с помощью моделей
Производительность
LocateAnything демонстрирует высокую производительность на нескольких эталонных тестах привязки, включая COCO/LVIS для обнаружения открытого множества, ScreenSpot-Pro для привязки GUI и различные тесты понимания макетов документов.
Эффективность вывода
С использованием бэкенда внимания la_flash и батч-гибридным выводом:
| Бэкенд | Время (4K проб) | Пиковая память |
|---|---|---|
| SDPA (плотные маски) | 8,26 с | 35,12 ГБ |
| la_flash (FlashAttention) | 8,03 с | 11,71 ГБ |
Открытый исходный код и доступность
LocateAnything-3B выпускается под лицензией NVIDIA для некоммерческих исследовательских и разработочных целей:
- Модель на HuggingFace: nvidia/LocateAnything-3B
- Код на GitHub: NVlabs/Eagle/Embodied
- Онлайн-демо: HuggingFace Spaces
- Технический отчёт: arXiv:2605.27365
- Страница проекта: NVIDIA Research
Требования к оборудованию
Оптимизировано для GPU NVIDIA (Ampere, Blackwell, Hopper, Lovelace) с точностью BF16 и KV-кэшем. Батч-инференс через бэкенд la_flash снижает пиковое потребление памяти с 35 ГБ до ~12 ГБ на A100.
Связанные ссылки
- Репозиторий GitHub: https://github.com/NVlabs/Eagle/tree/main/Embodied
- Модель на HuggingFace: https://huggingface.co/nvidia/LocateAnything-3B
- Онлайн-демо: https://huggingface.co/spaces/nvidia/LocateAnything
- Технический отчёт: https://arxiv.org/abs/2605.27365