NVIDIA, LocateAnything-3B 출시 – 병렬 박스 디코딩을 탑재한 오픈소스 비전-언어 그라운딩 모델
NVIDIA가 LocateAnything-3B를 오픈소스로 공개했습니다. 이 비전-언어 그라운딩 모델은 Parallel Box Decoding(PBD)을 통해 빠르고 정밀한 객체 위치 파악을 지원하며, 객체 감지, GUI 요소 그라운딩, OCR 위치 파악, 포인트 기반 그라운딩 등 다양한 도메인에서 활용 가능합니다.
2026년 6월 29일, NVIDIA가 LocateAnything-3B를 정식 출시했습니다. 이 오픈소스 비전-언어 그라운딩 모델은 자연어 명령으로부터 고속・고품질의 시각적 위치 파악을 가능하게 합니다. 이 모델은 **Parallel Box Decoding (PBD)**이라는 새로운 디코딩 방식을 도입하여, 바운딩 박스 좌표를 자동회귀 토큰 단위가 아닌 단일 병렬 단계로 예측하며, 이전 접근법 대비 최대 2.5배 높은 처리량을 달성합니다.
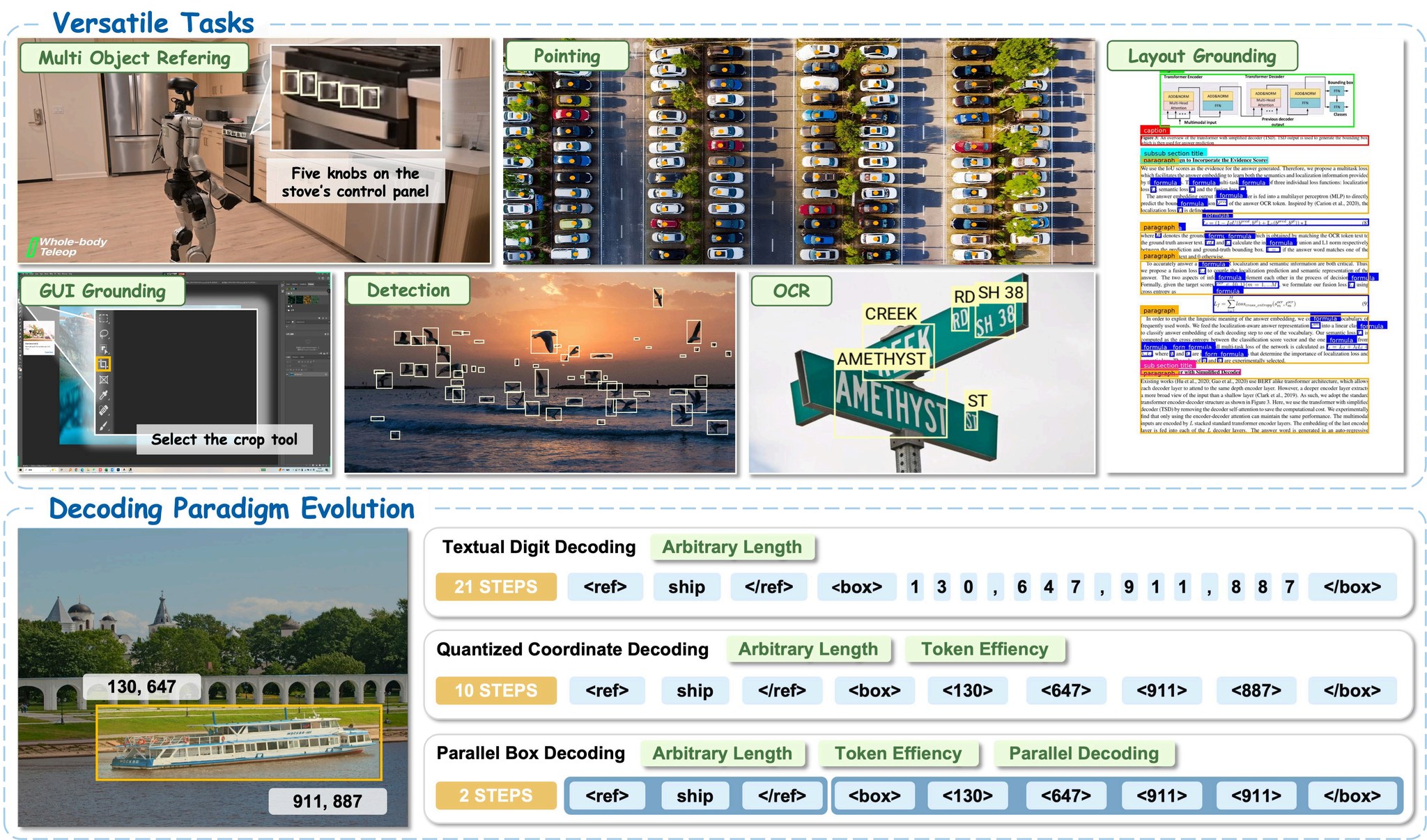 LocateAnything은 자연 장면, 로보틱스, GUI 상호작용, 문서 이해 등 다양한 도메인에서 정밀한 객체 위치 파악을 지원합니다.
LocateAnything은 자연 장면, 로보틱스, GUI 상호작용, 문서 이해 등 다양한 도메인에서 정밀한 객체 위치 파악을 지원합니다.
모델 개요
LocateAnything은 NVIDIA의 Eagle VLM 모델 패밀리의 일부로 개발된 범용 비전-언어 그라운딩 모델입니다. 다양한 위치 파악 작업을 지원합니다.
- 지시 표현 그라운딩 (Referring Expression Grounding): 자연어로 설명된 객체 위치 파악
- 개방형 객체 감지 (Open-Set Object Detection): 일반적인 객체와 긴꼬리(long-tail) 객체 카테고리 감지
- GUI 요소 그라운딩 (GUI Element Grounding): 에이전트 시스템을 위한 UI 요소 위치 파악
- 문서 레이아웃 그라운딩 (Document Layout Grounding): OCR 및 텍스트 위치 파악
- 포인트 기반 위치 파악 (Point-Based Localization): 포인팅을 통한 세밀한 공간 추론
이 모델은 NVIDIA의 Nemotron 및 Cosmos 제품 라인에 통합되어 컴퓨터 사용 및 시각적 그라운딩 기능을 제공합니다.
핵심 혁신: 병렬 박스 디코딩 (Parallel Box Decoding, PBD)
기존의 시각적 그라운딩 모델은 바운딩 박스 좌표를 자동회귀 방식으로 토큰 단위로 생성합니다. LocateAnything은 병렬 박스 디코딩을 도입합니다.
- 완전한 바운딩 박스 (
x1, y1, x2, y2)와 포인트를 병렬 구조화 단위로 예측 - 블록 단위 멀티토큰 예측 프레임워크 사용
- 기하학적 일관성을 유지하면서 2.5배 높은 처리량 달성
- 세 가지 추론 모드 지원:
- 고속 모드 (Fast Mode): 최대 속도를 위한 병렬 디코딩
- 저속 모드 (Slow Mode): 최대 정확도를 위한 자동회귀 디코딩
- 하이브리드 모드 (Hybrid Mode): 기본값; 병렬 디코딩을 사용하지만 포맷 이상 시 자동회귀로 폴백
기술 아키텍처
| 구성 요소 | 세부 정보 |
|---|---|
| 아키텍처 | Transformer 기반 VLM |
| 비전 인코더 | MoonViT (네이티브 해상도, 최대 2.5K) |
| 언어 모델 | Qwen2.5-3B-Instruct |
| 멀티모달 프로젝터 | MLP 프로젝터 |
| 총 파라미터 수 | 3B |
| 최대 이미지 해상도 | 2.5K (프로덕션), 배치 추론 시 최대 4K |
| 최대 시퀀스 길이 | 학습 25,600 토큰, 추론 생성 8,192 토큰 |
| 출력 포맷 | 블록 기반: 의미(Semantic), 상자(Box), 네거티브(Negative), 종료(End) 블록 |
학습 데이터
- 1,200만 개 고유 이미지, 1억 3,800만 개 이상의 쿼리, 7억 8,500만 개의 바운딩 박스
- 멀티 도메인: 자연 장면, 로보틱스, 주행, GUI, 문서
- 하이브리드 데이터 소스: 사람 큐레이션, 오픈소스, 모델 보조 합성 주석
성능
LocateAnything은 COCO/LVIS(개방형 감지), ScreenSpot-Pro(GUI 그라운딩), 다양한 문서 레이아웃 이해 벤치마크 등 여러 그라운딩 벤치마크에서 뛰어난 성능을 보여줍니다.
추론 효율성
la_flash 어텐션 백엔드와 배치 하이브리드 추론 사용 시:
| 백엔드 | 시간 (4K 프로브) | 최대 메모리 |
|---|---|---|
| SDPA (밀집 마스크) | 8.26초 | 35.12 GB |
| la_flash (FlashAttention) | 8.03초 | 11.71 GB |
오픈소스 및 이용 가능성
LocateAnything-3B는 비상업적 연구 및 개발 용도로 NVIDIA 라이선스 하에 배포됩니다.
- HuggingFace 모델: nvidia/LocateAnything-3B
- GitHub 코드: NVlabs/Eagle/Embodied
- 온라인 데모: HuggingFace Spaces
- 기술 신고: arXiv:2605.27365
- 프로젝트 페이지: NVIDIA 연구소
하드웨어 요구 사항
NVIDIA GPU(Ampere, Blackwell, Hopper, Lovelace)에 최적화되어 있으며, BF16 정밀도와 KV 캐시를 사용합니다. la_flash 백엔드를 통한 배치 추론은 A100에서 최대 메모리를 35GB에서 약 12GB로 줄여줍니다.
관련 링크
- GitHub 저장소: https://github.com/NVlabs/Eagle/tree/main/Embodied
- HuggingFace 모델: https://huggingface.co/nvidia/LocateAnything-3B
- 온라인 데모: https://huggingface.co/spaces/nvidia/LocateAnything
- 기술 신고: https://arxiv.org/abs/2605.27365