NVIDIA、LocateAnything-3Bを公開:並列ボックスデコードを備えたオープンソースの視覚言語グラウンディングモデル
NVIDIAが、並列ボックスデコード(PBD)を搭載した視覚言語グラウンディングモデルLocateAnything-3Bをオープンソース化。高速かつ高精度な物体位置特定を実現し、物体検出、GUI要素グラウンディング、OCR位置特定、ポイントベースのグラウンディングなど、多様なドメインをサポート
2026年6月29日、NVIDIAはLocateAnything-3Bを正式に公開しました。これはオープンソースの視覚言語グラウンディングモデルであり、自然言語による指示から高速かつ高品質な視覚的位置特定を可能にします。本モデルは並列ボックスデコード(Parallel Box Decoding, PBD)という新たなデコードパラダイムを導入しており、自己回帰的なトークン単位のデコードではなく、バウンディングボックスの座標全体を一度の並列ステップで予測することで、従来手法と比較して最大2.5倍のスループット向上を実現しています。
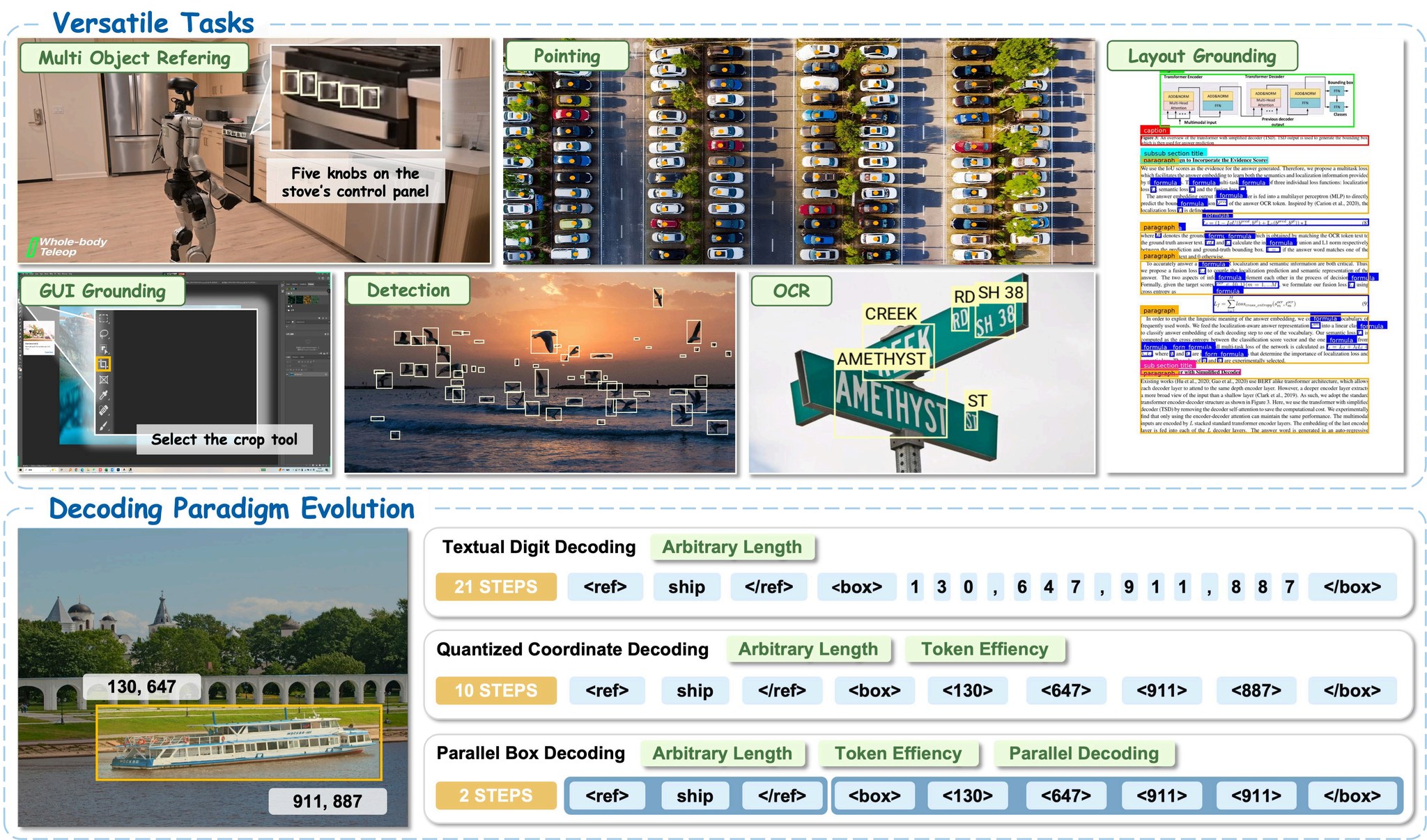 LocateAnythingは、自然シーン、ロボティクス、GUI操作、文書理解など、多様なドメインにおける高精度な物体位置特定を実現します。
LocateAnythingは、自然シーン、ロボティクス、GUI操作、文書理解など、多様なドメインにおける高精度な物体位置特定を実現します。
モデル概要
LocateAnythingは、NVIDIAのEagle VLMモデルファミリーの一部として開発された汎用視覚言語グラウンディングモデルです。以下の幅広い位置特定タスクをサポートしています。
- 参照表現グラウンディング(Referring Expression Grounding):自然言語で記述された物体を特定
- オープンセット物体検出(Open-Set Object Detection):一般的なカテゴリからロングテールな物体カテゴリまで検出
- GUI要素グラウンディング:エージェントシステム向けにUI要素を特定
- 文書レイアウトグラウンディング:OCRおよびテキスト位置特定
- ポイントベースの位置特定:ポインティングによる細かい空間推論
本モデルはNVIDIAのNemotronおよびCosmos製品ラインに統合され、コンピュータ操作や視覚グラウンディング機能を強化しています。
中核となる革新:並列ボックスデコード(PBD)
従来の視覚グラウンディングモデルは、バウンディングボックスの座標を自己回帰的にトークン単位で生成していました。LocateAnythingは並列ボックスデコードを導入します。
- バウンディングボックス(x1, y1, x2, y2)やポイントを並列構造単位で完全に予測
- ブロック単位のマルチトークン予測フレームワークを使用
- 幾何学的整合性を犠牲にすることなく2.5倍のスループット向上を達成
- 3つの推論モードをサポート:
- Fastモード:最大速度のための並列デコード
- Slowモード:最大精度のための自己回帰デコード
- Hybridモード:デフォルト。並列デコードを基本とし、フォーマットの不整合が発生した場合に自己回帰デコードにフォールバック
技術アーキテクチャ
| コンポーネント | 詳細 |
|---|---|
| アーキテクチャ | TransformerベースのVLM |
| ビジョンエンコーダ | MoonViT(ネイティブ解像度、最大2.5K) |
| 言語モデル | Qwen2.5-3B-Instruct |
| マルチモーダルプロジェクタ | MLPプロジェクタ |
| 総パラメータ数 | 3B |
| 最大画像解像度 | 2.5K(本番環境)、バッチ推論時は最大4K |
| 最大シーケンス長 | 25,600トークン(トレーニング時)、8,192トークン生成(推論時) |
| 出力形式 | ブロックベース:セマンティックブロック、ボックスブロック、ネガティブブロック、エンドブロック |
トレーニングデータ
- 1,200万枚のユニーク画像、1億3,800万以上のクエリ、7億8,500万のバウンディングボックス
- マルチドメイン:自然シーン、ロボティクス、運転、GUI、ドキュメント
- ハイブリッドデータソース:人間によるキュレーション、オープンソース、モデル支援による合成アノテーション
パフォーマンス
LocateAnythingは、オープンセット検出向けのCOCO/LVIS、GUIグラウンディング向けのScreenSpot-Pro、各種文書レイアウト理解ベンチマークなど、複数のグラウンディングベンチマークで優れたパフォーマンスを示しています。
推論効率
la_flashアテンションバックエンドをバッチハイブリッド推論で使用した場合:
| バックエンド | 時間(4Kプローブ) | ピークメモリ |
|---|---|---|
| SDPA(高密度マスク) | 8.26秒 | 35.12 GB |
| la_flash(FlashAttention) | 8.03秒 | 11.71 GB |
オープンソースと入手方法
LocateAnything-3Bは、非商用の研究・開発用途向けにNVIDIAライセンスの下で公開されています。
- HuggingFaceモデル:nvidia/LocateAnything-3B
- GitHubコード:NVlabs/Eagle/Embodied
- オンラインデモ:HuggingFace Spaces
- 技術報告書:arXiv:2605.27365
- プロジェクトページ:NVIDIA Research
ハードウェア要件
NVIDIA GPU(Ampere、Blackwell、Hopper、Lovelace)向けに最適化されており、BF16精度とKVキャッシュを利用します。la_flashバックエンドによるバッチ推論により、A100上でのピークメモリを35GBから約12GBに削減します。