NVIDIA publica LocateAnything-3B - Modelo de grounding visión-lenguaje de código abierto con decodificación paralela de cajas
NVIDIA publica como código abierto LocateAnything-3B, un modelo de grounding visión-lenguaje que presenta Decodificación Paralela de Cajas (PBD) para una localización rápida y precisa de objetos, compatible con detección de objetos, grounding de elementos GUI, localización OCR y grounding basado en puntos en diversos dominios.
El 29 de junio de 2026, NVIDIA lanzó oficialmente LocateAnything-3B, un modelo de grounding visión-lenguaje de código abierto que permite una localización visual rápida y de alta calidad a partir de instrucciones en lenguaje natural. El modelo introduce la Decodificación Paralela de Cajas (PBD, Parallel Box Decoding), un novedoso paradigma de decodificación que predice coordenadas completas de cajas delimitadoras en un único paso paralelo en lugar de una decodificación autoregresiva token por token, logrando hasta 2,5 veces más rendimiento en comparación con enfoques anteriores.
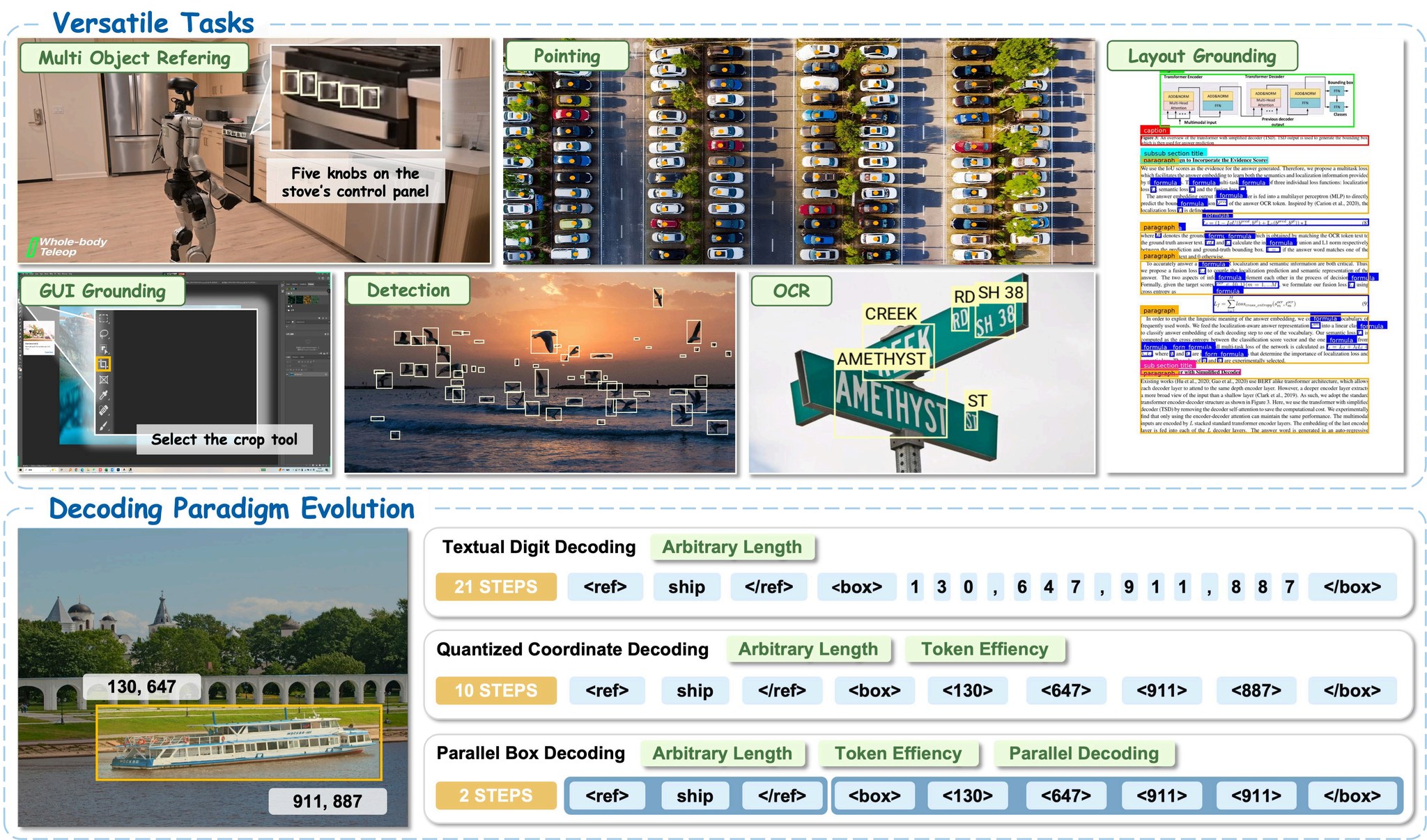 LocateAnything permite una localización precisa de objetos en diversos dominios, incluyendo escenas naturales, robótica, interacción GUI y comprensión de documentos.
LocateAnything permite una localización precisa de objetos en diversos dominios, incluyendo escenas naturales, robótica, interacción GUI y comprensión de documentos.
Descripción general del modelo
LocateAnything es un modelo de grounding visión-lenguaje generalista desarrollado como parte de la familia de modelos Eagle VLM de NVIDIA. Admite una amplia gama de tareas de localización:
- Grounding de expresiones referenciales: Localizar objetos descritos mediante lenguaje natural.
- Detección de objetos de conjunto abierto: Detectar categorías de objetos comunes y de cola larga.
- Grounding de elementos GUI: Localizar elementos de interfaz de usuario para sistemas agentivos.
- Grounding de diseño de documentos: OCR y localización de texto.
- Localización basada en puntos: Razonamiento espacial de grano fino mediante señalización.
El modelo se ha integrado en las líneas de productos Nemotron y Cosmos de NVIDIA, potenciando funciones de uso informático y grounding visual.
Innovación central: Decodificación Paralela de Cajas (PBD)
Los modelos tradicionales de grounding visual generan coordenadas de cajas delimitadoras de forma autoregresiva, token por token. LocateAnything introduce la Decodificación Paralela de Cajas:
- Predice cajas delimitadoras completas (
x1, y1, x2, y2) y puntos en unidades estructuradas paralelas. - Utiliza un marco de predicción multitoken por bloques.
- Logra 2,5 veces más rendimiento sin sacrificar la consistencia geométrica.
- Admite tres modos de inferencia:
- Modo rápido: Decodificación paralela para máxima velocidad.
- Modo lento: Decodificación autoregresiva para máxima precisión.
- Modo híbrido: Predeterminado; decodificación paralela con retroceso a autoregresiva en caso de irregularidades en el formato.
Arquitectura técnica
| Componente | Detalles |
|---|---|
| Arquitectura | VLM basado en Transformer |
| Codificador visual | MoonViT (resolución nativa, hasta 2,5K) |
| Modelo de lenguaje | Qwen2.5-3B-Instruct |
| Proyector multimodal | Proyector MLP |
| Parámetros totales | 3B |
| Resolución máxima de imagen | 2,5K (producción), hasta 4K con inferencia por lotes |
| Longitud máxima de secuencia | 25.600 tokens (entrenamiento), 8.192 tokens de generación (inferencia) |
| Formato de salida | Basado en bloques: bloques semántico, de caja, negativo y final |
Datos de entrenamiento
- 12 millones de imágenes únicas, más de 138 millones de consultas, 785 millones de cajas delimitadoras.
- Multidominio: escenas naturales, robótica, conducción, GUI, documentos.
- Fuentes de datos híbridas: curadas por humanos, de código abierto, anotaciones sintéticas asistidas por modelos.
Rendimiento
LocateAnything demuestra un rendimiento sólido en múltiples puntos de referencia de grounding, incluidos COCO/LVIS para detección de conjunto abierto, ScreenSpot-Pro para grounding GUI y varios puntos de referencia de comprensión de diseño de documentos.
Eficiencia de inferencia
Usando el backend de atención la_flash con inferencia híbrida por lotes:
| Backend | Tiempo (sonda 4K) | Memoria máxima |
|---|---|---|
| SDPA (máscaras densas) | 8,26 s | 35,12 GB |
| la_flash (FlashAttention) | 8,03 s | 11,71 GB |
Código abierto y disponibilidad
LocateAnything-3B se publica bajo la Licencia NVIDIA para uso no comercial de investigación y desarrollo:
- Modelo HuggingFace: nvidia/LocateAnything-3B
- Código GitHub: NVlabs/Eagle/Embodied
- Demo en línea: HuggingFace Spaces
- Informe técnico: arXiv:2605.27365
- Página del proyecto: NVIDIA Research
Requisitos de hardware
Optimizado para GPUs NVIDIA (Ampere, Blackwell, Hopper, Lovelace) con precisión BF16 y caché KV. La inferencia por lotes mediante el backend la_flash reduce la memoria máxima de 35 GB a aproximadamente 12 GB en A100.
Enlaces relacionados
- Repositorio GitHub: https://github.com/NVlabs/Eagle/tree/main/Embodied
- Modelo HuggingFace: https://huggingface.co/nvidia/LocateAnything-3B
- Demo en línea: https://huggingface.co/spaces/nvidia/LocateAnything
- Informe técnico: https://arxiv.org/abs/2605.27365