Pixel-Reasoner:开源像素级视觉推理模型发布
news
Pixel-Reasoner 基于 Qwen2,具备全局与局部像素级视觉理解和推理能力,支持细节放大分析,推动视觉语言模型新进展。
Pixel-Reasoner 是一款基于 Qwen2 的开源视觉语言模型,专注于提升模型在像素级别的视觉理解和推理能力。该模型不仅能够对整幅图像进行全局分析,还支持对局部区域进行放大和细致观察,从而更好地捕捉图像中的细节信息。
主要特性
- 像素级推理能力:Pixel-Reasoner 能够直接在图像的像素空间进行推理,不再局限于传统的文本推理方式。
- 全局与局部理解结合:模型既能整体把握画面内容,也能通过"放大"操作聚焦于细节区域,实现更精细的分析。
- 好奇心驱动的训练机制:通过引入好奇心奖励机制,鼓励模型主动探索和使用像素级操作,提升视觉推理的多样性和准确性。
- 开源可用:模型、数据集及相关代码均已开源,便于社区用户下载和体验。
像素级推理新范式
Pixel-Reasoner 引入了"像素空间推理(Pixel-Space Reasoning)"的全新理念。与传统视觉语言模型仅依赖文本推理不同,Pixel-Reasoner 能够直接在图像像素层面进行分析和操作。
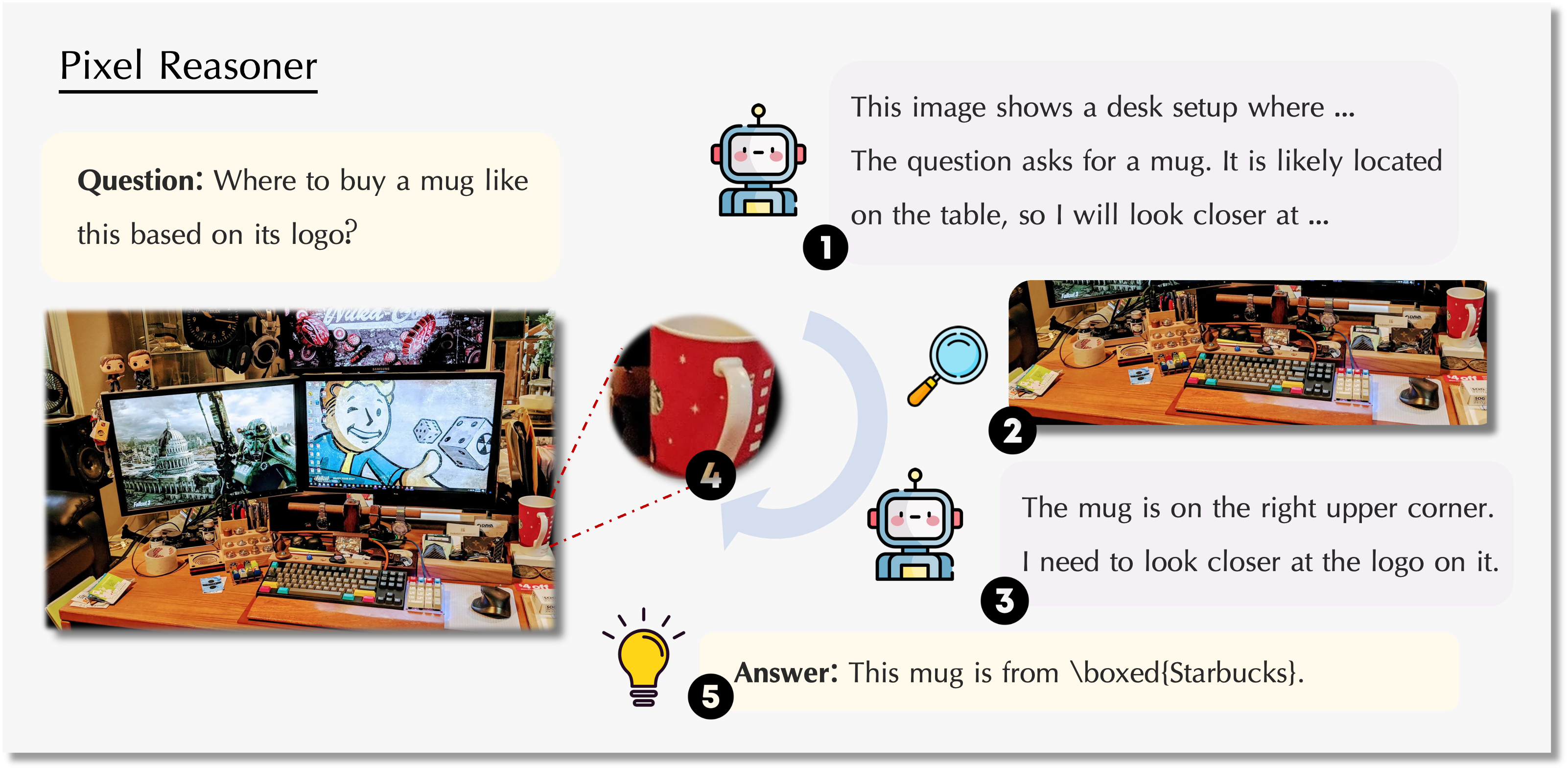 如上图所示,模型不仅能整体理解画面,还能通过放大、选区等操作,聚焦于图像的细节区域,提升对复杂视觉内容的理解能力。
如上图所示,模型不仅能整体理解画面,还能通过放大、选区等操作,聚焦于图像的细节区域,提升对复杂视觉内容的理解能力。
训练难点与创新机制
在模型训练过程中,团队发现现有视觉语言模型在像素级推理能力上存在"学习陷阱"——模型更擅长文本推理,面对像素级操作时容易失败,导致缺乏动力去主动探索视觉操作。
 上图展示了模型在像素空间推理初期遇到的瓶颈:由于初始能力不足,模型更倾向于回避视觉操作,影响了像素级推理能力的培养。
上图展示了模型在像素空间推理初期遇到的瓶颈:由于初始能力不足,模型更倾向于回避视觉操作,影响了像素级推理能力的培养。
为此,Pixel-Reasoner 采用了"好奇心驱动"的强化学习机制,通过奖励模型主动尝试像素级操作,逐步提升其在视觉空间的推理能力。
数据合成与训练流程
Pixel-Reasoner 的训练分为两个阶段:
- 指令微调:通过合成包含视觉操作的推理轨迹,让模型熟悉各种像素级操作。
- 好奇心驱动强化学习:引入奖励机制,鼓励模型在推理过程中主动探索和使用视觉操作。
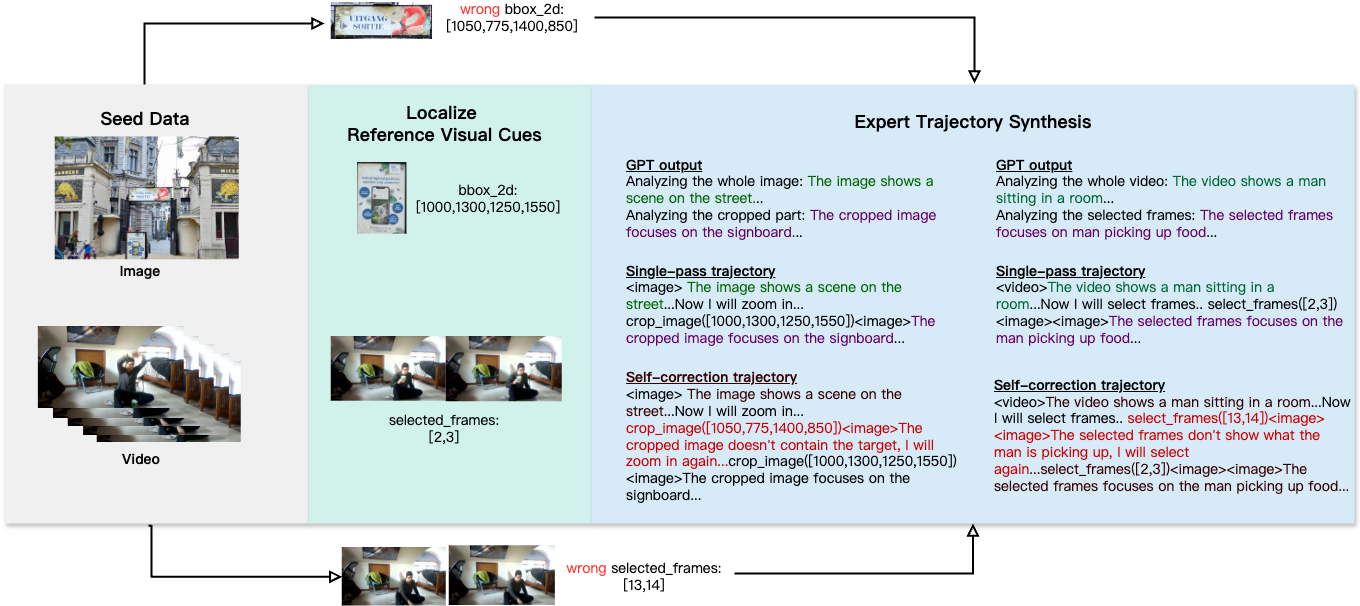 如上图所示,团队通过高分辨率图片和视频,结合自动与人工标注,生成多样化的推理数据,帮助模型学习如何在视觉空间中分析和自我纠错。
如上图所示,团队通过高分辨率图片和视频,结合自动与人工标注,生成多样化的推理数据,帮助模型学习如何在视觉空间中分析和自我纠错。
典型应用场景
Pixel-Reasoner 尤其适合以下场景:
- 需要识别图像中微小物体或细节的任务
- 复杂图片或视频中多区域、多层次信息的理解
- 需要结合整体与局部信息的视觉推理任务
应用场景
Pixel-Reasoner 适用于需要细致视觉理解的场景,例如:
- 复杂图片或视频内容的分析
- 小物体、细微关系或嵌入文字的识别
- 需要结合全局与局部信息的视觉任务
相关链接
- 论文地址:https://arxiv.org/abs/2505.15966
- 官方主页:https://tiger-ai-lab.github.io/Pixel-Reasoner/
- HuggingFace模型:https://huggingface.co/TIGER-Lab/PixelReasoner-RL-v1
- 在线体验:https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
本文内容参考自 Pixel-Reasoner 官方资料及论文。
评论
使用 GitHub 登录后即可参与讨论。