Sand AI发布MAGI-1:规模化自回归视频生成模型
Sand AI开源了MAGI-1,这是一个能够逐块生成视频的自回归模型,提供24B和4.5B参数版本,支持多种视频生成方式
Sand AI团队于4月21日正式开源了MAGI-1视频生成模型,并计划在4月底发布4.5B参数版本。这是一个能够通过自回归方式预测视频片段序列的世界模型,支持文本到视频(T2V)、图像到视频(I2V)和视频到视频(V2V)多种生成方式。
技术创新
MAGI-1采用了多项技术创新,使其在视频生成领域展现出独特优势:
基于Transformer的VAE
- 采用基于Transformer的变分自编码器,实现8倍空间压缩和4倍时间压缩
- 具有最快的平均解码时间,同时保持高质量的重建效果
自回归去噪算法
MAGI-1通过块状自回归方式生成视频,而非一次性生成。每个块(24帧)被整体降噪,当当前块达到一定降噪程度时,下一块的生成即可开始。这种设计支持最多四个块的并行处理,提高视频生成效率。

扩散模型架构
MAGI-1基于扩散变换器构建,融合了多项关键创新以提高训练效率和大规模稳定性。这些改进包括Block-Causal Attention(块因果注意力)、Parallel Attention Block(并行注意力块)、QK-Norm和GQA、FFN中的Sandwich Normalization(三明治标准化)、SwiGLU和Softcap Modulation(软上限调制)等。
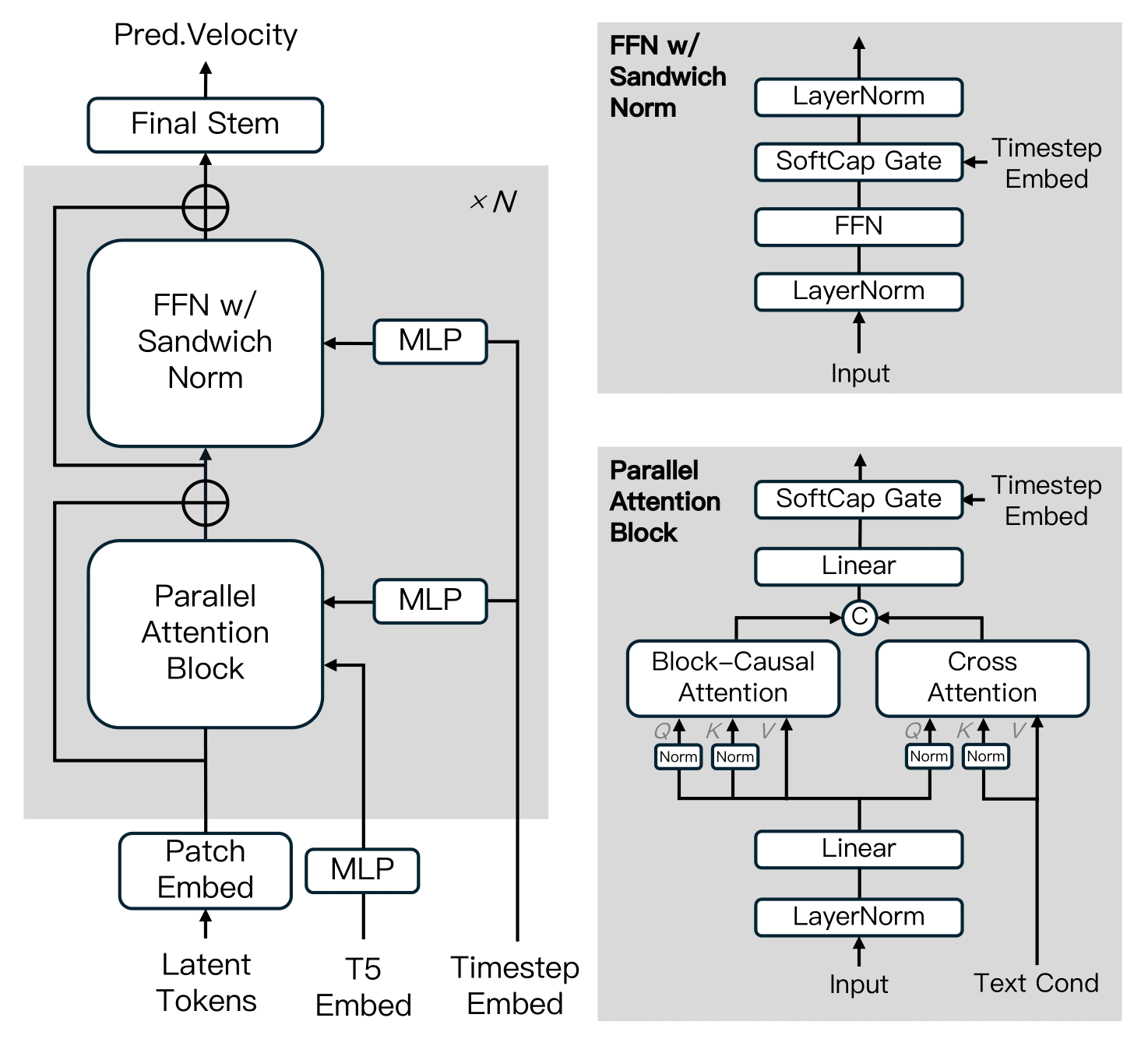
蒸馏算法
模型采用了快捷蒸馏方法,训练单一的基于速度的模型以支持可变推理预算。通过强制自一致性约束(一个大步等同于两个小步),模型学习在多个步长上近似流匹配轨迹。在训练期间,从 64, 32, 16, 8 循环采样步长,并结合无分类器引导蒸馏以保持条件对齐,从而实现高效推理,同时最小化保真度损失。
模型版本
Sand AI团队提供了多个版本的MAGI-1预训练权重,包括24B和4.5B模型,以及相应的蒸馏和量化模型:
| 模型 | 推荐硬件 | |
- |
-- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 或 RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
性能评估
物理评估
得益于自回归架构的天然优势,MAGI-1在Physics-IQ基准测试中通过视频延续,在预测物理行为方面取得了远超所有现有模型的精度。
在Physics-IQ评分中,MAGI的视频到视频(V2V)模式达到了56.02分,而其图像到视频(I2V)模式也达到了30.23分,明显优于其他开源和闭源商业模型如VideoPoet、Kling1.6和Sora等。
运行方法
MAGI-1支持通过Docker环境(推荐)或源代码两种方式运行。用户可以通过调整run.sh脚本中的参数,灵活控制输入和输出以满足不同需求:
--mode: 指定操作模式(t2v、i2v或v2v)--prompt: 用于视频生成的文本提示--image_path: 图像文件路径(仅在i2v模式下使用)--prefix_video_path: 前缀视频文件路径(仅在v2v模式下使用)--output_path: 生成的视频文件保存路径
评论
使用 GitHub 登录后即可参与讨论。