昆仑万维发布SkyReels-V2无限时长电影生成模型
昆仑万维SkyReels团队发布并开源SkyReels-V2,这是全球首个使用扩散强迫框架的无限时长电影生成模型,能够生成高质量、长时间的视频内容
![]()
昆仑万维发布SkyReels-V2无限时长电影生成模型
4月21日,昆仑万维SkyReels团队正式发布并开源SkyReels-V2——全球首个使用扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型。该模型通过结合多模态大语言模型(MLLM)、多阶段预训练、强化学习和扩散强迫框架来实现协同优化,能够生成30秒、40秒甚至更长的高质量视频。
🎥 效果演示
以上演示展示了使用SkyReels-V2扩散强迫模型生成的30秒视频。
技术创新
SkyReels-V2能够达到高质量视频生成效果,主要依靠以下几项技术创新:
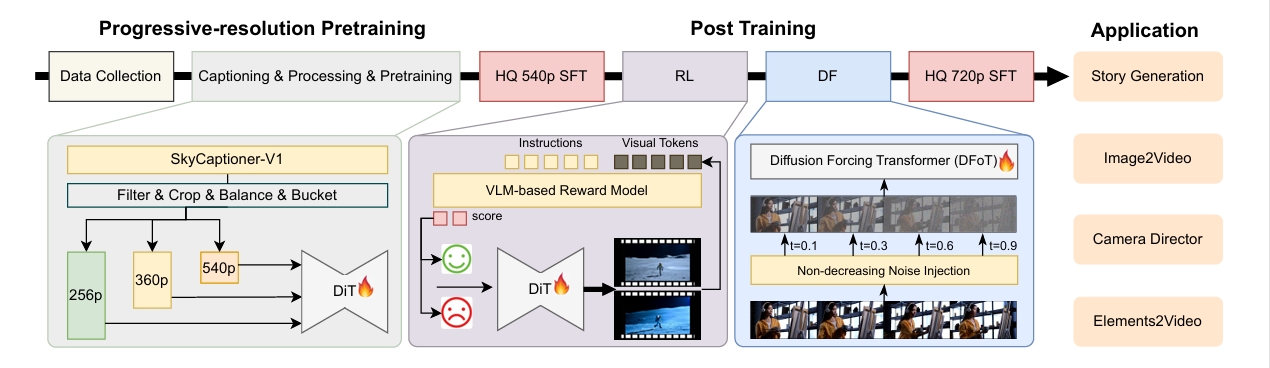
1. 影视级视频理解模型:SkyCaptioner-V1
团队设计了一种结构化的视频表示方法,将多模态LLM的一般描述与子专家模型的详细镜头语言相结合。这种方法能够识别视频中的主体类型、外观、表情、动作和位置等信息。
SkyCaptioner-V1能够高效理解视频数据,生成符合原始结构信息的多样化描述,不仅能理解视频的一般内容,还能捕捉到电影场景中的专业镜头语言,显著提高了生成视频的提示词遵循能力。该模型现已开源,可直接使用。
2. 针对运动的偏好优化
通过强化学习训练,使用人工标注和合成失真数据,解决了现有视频生成模型在动态扭曲、不合理等问题。团队设计了一个半自动数据收集管道,能够高效地生成偏好对比数据对。
通过这种方式,SkyReels-V2在运动动态方面表现优异,能够生成流畅且逼真的视频内容,满足对高质量运动动态的需求。
3. 高效的扩散强迫框架
为实现长视频生成能力,团队提出了扩散强迫后训练方法。通过微调预训练的扩散模型,将其转化为扩散强迫模型,不仅减少了训练成本,还显著提高了生成效率。
团队采用非递减噪声时间表,将连续帧的去噪时间表搜索空间从O(1e48)降低到O(1e32),从而实现了长视频的高效生成。
4. 渐进式分辨率预训练与多阶段后训练优化
为开发专业的影视生成模型,团队的多阶段质量保证框架整合了来自三个主要来源的数据:通用数据集、自收集媒体和艺术资源库。
在此数据基础上,团队首先通过渐进式分辨率预训练建立基础视频生成模型,然后进行四阶段的后续训练增强:初始概念平衡的监督微调、运动特定的强化学习训练、扩散强迫框架和高质量SFT。
性能表现
SkyReels-V2在多项评测中展现出优异的性能:
-
在SkyReels-Bench的T2V多维度人工评测中,SkyReels-V2在指令遵循(3.15)和一致性(3.35)方面获得最高水准,同时在视频质量(3.34)和运动质量(2.74)上保持第一梯队。
-
在VBench1.0自动化评估中,SkyReels-V2在总分(83.9%)和质量分(84.7%)上均优于所有对比模型,包括HunyuanVideo-13B和Wan2.1-14B。
应用场景
SkyReels-V2为多个实际应用场景提供了强大支持:
-
故事生成:能够生成理论上无限时长的视频,通过滑动窗口方法和稳定化技术,生成具有连贯叙事的长镜头视频。
-
图像到视频合成:提供两种图像到视频的生成方法,在所有质量维度上均优于其他开源模型,并与闭源模型表现相当。
-
摄像导演功能:通过专门筛选的样本和微调实验,显著提升了摄影效果,特别是在摄像机运动的流畅性和多样性方面。
-
元素到视频生成:基于SkyReels-V2基座模型开发的SkyReels-A2方案,能够将任意视觉元素组合成由文本提示引导的连贯视频。
模型开源
昆仑万维SkyReels团队已将SkyCaptioner-V1和SkyReels-V2系列模型(包括扩散强迫、文本到视频、图像到视频、摄像导演和元素到视频模型)的各种尺寸(1.3B、5B、14B)完全开源,以促进学术界和工业界的进一步研究和应用。
评论
使用 GitHub 登录后即可参与讨论。