TTT-Video:长视频生成技术
研究人员利用Test-Time Training技术,基于CogVideoX 5B模型开发了能生成长达63秒连贯视频的TTT-Video模型
研究人员最近公开了名为TTT-Video的开源项目,这项技术突破了传统AI视频生成的时长限制,能够生成长达63秒的连贯视频内容。该技术通过创新的Test-Time Training(测试时训练)方法解决了长视频生成过程中的内容一致性问题。
解决视频生成的关键挑战
目前大多数AI视频生成模型只能创建3-5秒的短视频片段。这是因为视频生成使用的Transformer模型在处理长序列时,自注意力机制的计算成本呈二次方增长,导致无法高效处理长视频。
TTT-Video通过创新的方式解决了这一问题:保留原始预训练模型的注意力层用于处理每个3秒片段的局部注意力,同时引入特殊的Test-Time Training层处理全局上下文的长距离关系。
技术实现方式
该项目是基于CogVideoX 5B模型(一种用于文本到视频生成的扩散Transformer)进行改进的,主要创新点包括:
- 引入TTT层处理全局序列及其反转版本,通过门控残差连接组合输出
- 延长上下文:通过将每个片段与文本和视频嵌入交错处理
- 分阶段训练:首先在原始预训练的3秒视频长度上进行微调,然后逐步在9秒、18秒、30秒和63秒的视频长度上训练
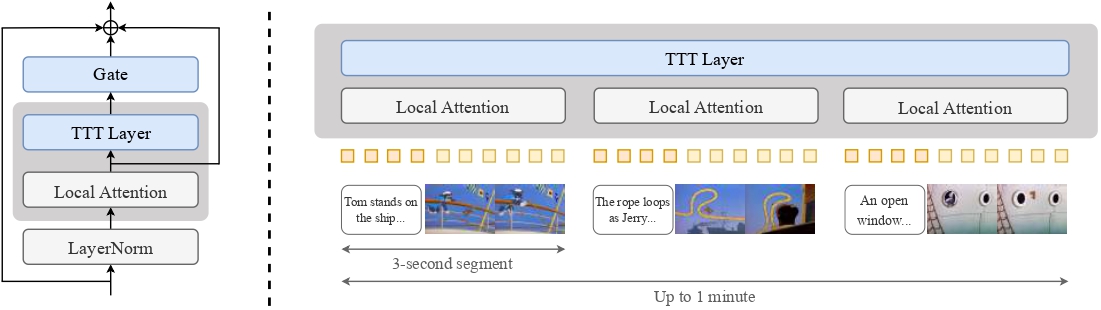
TTT-Video模型架构:通过TTT层处理全局序列,并与局部注意力机制结合
研究团队以经典动画《猫和老鼠》为测试案例,能够生成风格一致、动作连贯的一分钟左右的动画视频,虽然受限于5B参数量,生成质量还有提升空间。
令人惊叹的生成效果
<video style={{ width: '100%', maxWidth: '680px' }} src="https://test-time-training.github.io/video-dit/videos/63s-demo/homeless.mp4" controls />
TTT-Video最令人印象深刻的地方在于它能够一次性生成长达一分钟的《猫和老鼠》风格动画,而且:
- 不需要任何编辑、拼接或后期处理
- 生成的内容完全是原创的,原动画片中不存在这些场景
- 角色动作、场景转换和故事情节保持连贯

TTT-Video生成的《猫和老鼠》风格动画帧示例
对AI创作者的意义
这项技术对使用ComfyUI等工具的AI创作者意味着:
- 未来可能实现更长、更有叙事性的AI视频生成
- 解决了视频生成中一致性和连贯性的关键问题
- 为创作者提供了创建更长视频内容的可能性,而无需手动拼接多个片段
评论
使用 GitHub 登录后即可参与讨论。