StdGEN: 从单一图像生成语义分解的3D角色
ComfyUI Wikinews
清华大学与腾讯AI实验室联合推出StdGEN,一种创新的管道,可从单一图像生成语义分解的高质量3D角色,实现身体、衣物和头发等组件的分离

清华大学与腾讯AI实验室的研究团队近日发布了一项创新技术StdGEN(Semantic-Decomposed 3D Character Generation),该技术能够从单一图像生成语义分解的高质量3D角色模型。这项研究已被计算机视觉顶级会议CVPR 2025接收。
技术创新
StdGEN通过一种创新的管道流程,实现了三大关键特性:
- 语义分解能力:生成的3D角色模型可以在身体、衣物和头发等语义组件上完全分离,便于后续编辑和定制。
- 高效性:仅需3分钟即可完成从单一图像到完整3D角色的生成过程。
- 高质量重建:生成的3D模型具有精细的几何细节和纹理。
核心技术
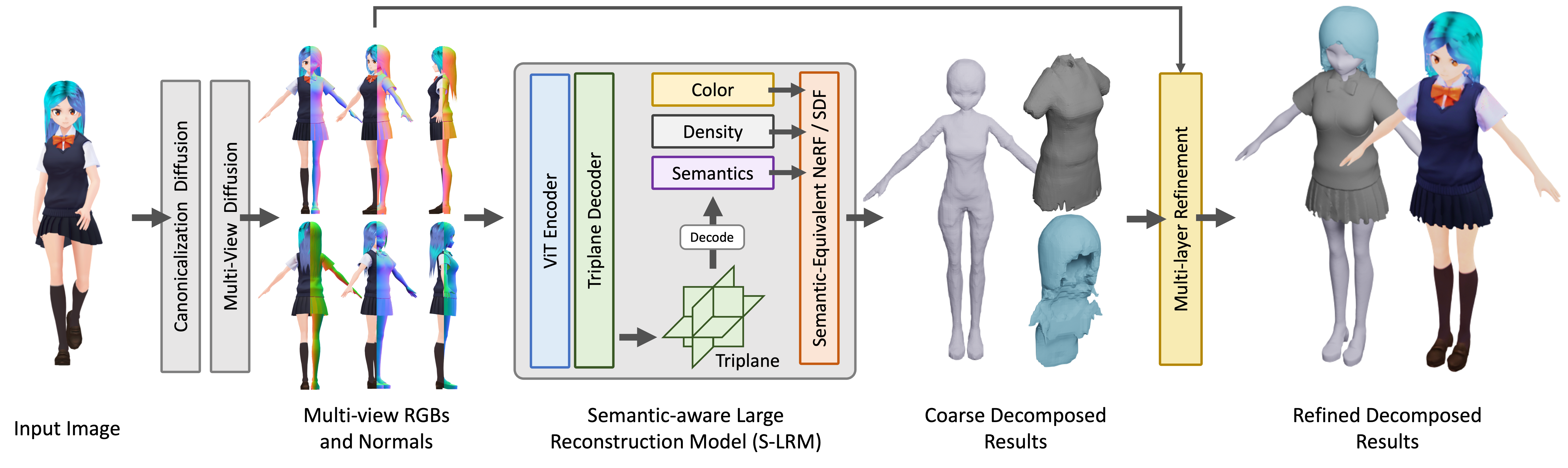 StdGEN的核心是研究团队提出的语义感知大型重建模型(S-LRM),这是一种基于Transformer的可泛化模型,能够以前馈方式从多视图图像联合重建几何形状、颜色和语义信息。
StdGEN的核心是研究团队提出的语义感知大型重建模型(S-LRM),这是一种基于Transformer的可泛化模型,能够以前馈方式从多视图图像联合重建几何形状、颜色和语义信息。
此外,该方法还引入了以下创新:
- 差分多层语义表面提取方案,用于从S-LRM重建的混合隐式场中获取网格
- 专用的高效多视图扩散模型
- 迭代多层表面细化模块
应用前景
这项技术在虚拟现实、游戏开发和电影制作等领域具有广泛的应用前景。与现有方法相比,StdGEN在几何形状、纹理和可分解性方面都取得了显著提升,为用户提供了即用型的语义分解3D角色,并支持灵活的定制。
研究团队已经开源了推理代码、数据集和预训练检查点,同时还提供了在线HuggingFace Gradio演示。
评论
使用 GitHub 登录后即可参与讨论。