快手推出CineMaster:突破3D感知的智能视频生成框架
快手正式发布CineMaster文本到视频生成框架,通过3D感知技术实现高品质视频内容创作
快手近期发布了名为 CineMaster 的全新文本到视频生成框架,标志着视频创作领域的一次重要突破。该框架具备强大的3D感知能力,被誉为视频版本的 ControlNet,为创作者提供了前所未有的精确控制能力,能够精细控制视频中的位置、运动轨迹以及3D空间的布局。
CineMaster 技术上的创新
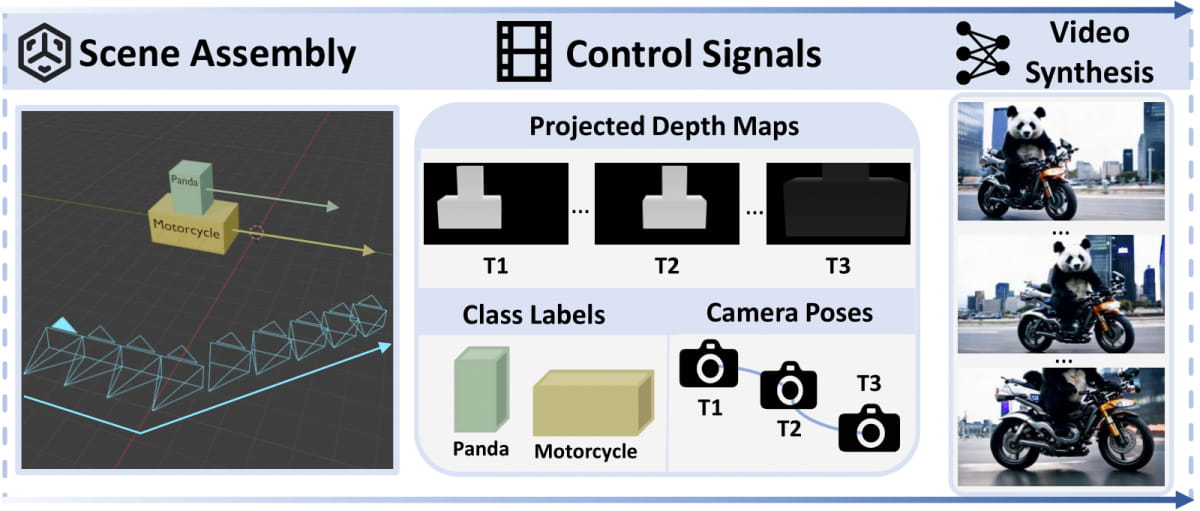
CineMaster采用了创新的两阶段框架设计:
快手发布CineMaster:突破性文本到视频生成框架,具备3D感知能力
CineMaster 框架亮点
CineMaster框架的核心亮点在于其对视频生成的高度可控性。用户不仅可以创作出完全可控的视频内容,还能提取视频中的3D信息进行二次创作和编辑,实现风格迁移。这使得CineMaster成为一个极具创作潜力的工具,允许用户在3D空间中精确放置物体并灵活调节摄像机角度。
精确控制物体和相机运动
CineMaster使得创作者能够通过多种控制信号精确操控视频中物体的位置以及相机的运动轨迹。这意味着用户不仅能生成动态变化的场景,还能够在场景中嵌入复杂的3D元素,为视频创作带来极大的自由度。
CineMaster 的两阶段工作流程
CineMaster的工作流程分为两个阶段:
-
交互式工作流程:用户通过定位物体的边界框,并定义3D空间中的摄像机运动,直观地构建控制信号。这一阶段为用户提供了直观且易于操作的3D感知环境。
-
控制信号生成:在第一阶段生成的控制信号(包括深度图、摄像机轨迹和对象类别标签)被输入到文本到视频的扩散模型中,指导生成符合用户需求的视频内容。
数据集标注管道
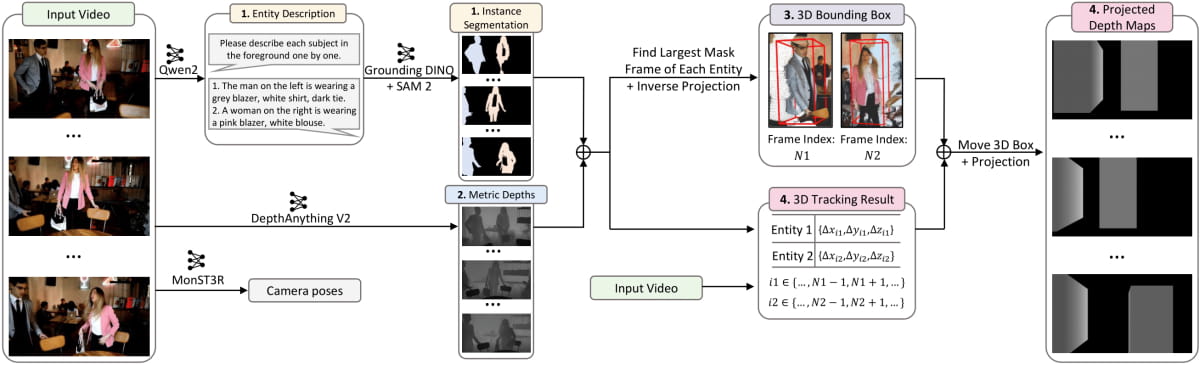
为了克服3D框和摄像机姿态标注数据的匮乏,快手构建了一个自动化的数据注释管道,从大规模视频数据中提取3D边界框和摄像机轨迹。这一管道包括以下步骤:
- 实例分割:从视频的前景提取实例分割结果。
- 深度估计:使用DepthAnything V2生成度量深度图。
- 3D点云和框计算:通过逆投影技术计算每个实体的3D点云,并利用最小体积法计算每个实体的3D边界框。
- 实体跟踪和3D框调整:通过点跟踪技术计算每帧的3D边界框,并将整个3D场景投影到深度图中。
性能超越现有方法
CineMaster在广泛的定性和定量实验中表现出色,显著优于现有的其他方法,特别是在生成移动物体和静态摄像机、静态物体和移动摄像机、以及移动物体和移动摄像机这三种场景中,CineMaster都展现出了卓越的控制能力,能够根据用户需求灵活生成各种复杂的场景。
技术架构与创新
CineMaster框架的设计创新性地采用了语义布局ControlNet。该架构包括一个语义注入器和一个基于DiT的ControlNet。语义注入器通过融合3D空间布局和类别标签,为模型提供必要的控制信号。而基于DiT的ControlNet则进一步处理这些特征并增强模型的表示能力。此外,摄像头适配器能够注入摄像机轨迹,从而实现物体运动和摄像机运动的联合控制。
为创作者提供了一个高度灵活和可控的文本到视频生成平台,带来了前所未有的3D创作自由度。随着技术的不断迭代与优化,CineMaster有望在未来引领视频创作和编辑的新潮流,为用户提供更加丰富、细腻的创作体验。
项目开源状态
- 暂未有开源及相关内容
CineMaster 相关链接
项目页面:https://cinemaster-dev.github.io/ 论文地址:https://arxiv.org/pdf/2502.08639
评论
使用 GitHub 登录后即可参与讨论。