NVIDIA 发布 LocateAnything-3B —— 开源视觉语言定位模型,支持并行框解码
NVIDIA 开源 LocateAnything-3B,一款采用并行框解码(PBD)的视觉语言定位模型,能够快速精准地定位物体,支持物体检测、GUI 元素定位、OCR 定位以及基于点的定位,适用于多种领域
2026 年 6 月 29 日,NVIDIA 正式发布 LocateAnything-3B,一款开源的视觉语言定位模型,能够根据自然语言指令快速、高质量地完成视觉定位。该模型引入了 并行框解码(Parallel Box Decoding, PBD),这是一种新颖的解码范式,可以在单个并行步骤中预测完整的边界框坐标,而非逐词自回归解码,相比之前的方法实现了 高达 2.5 倍的吞吐量提升。
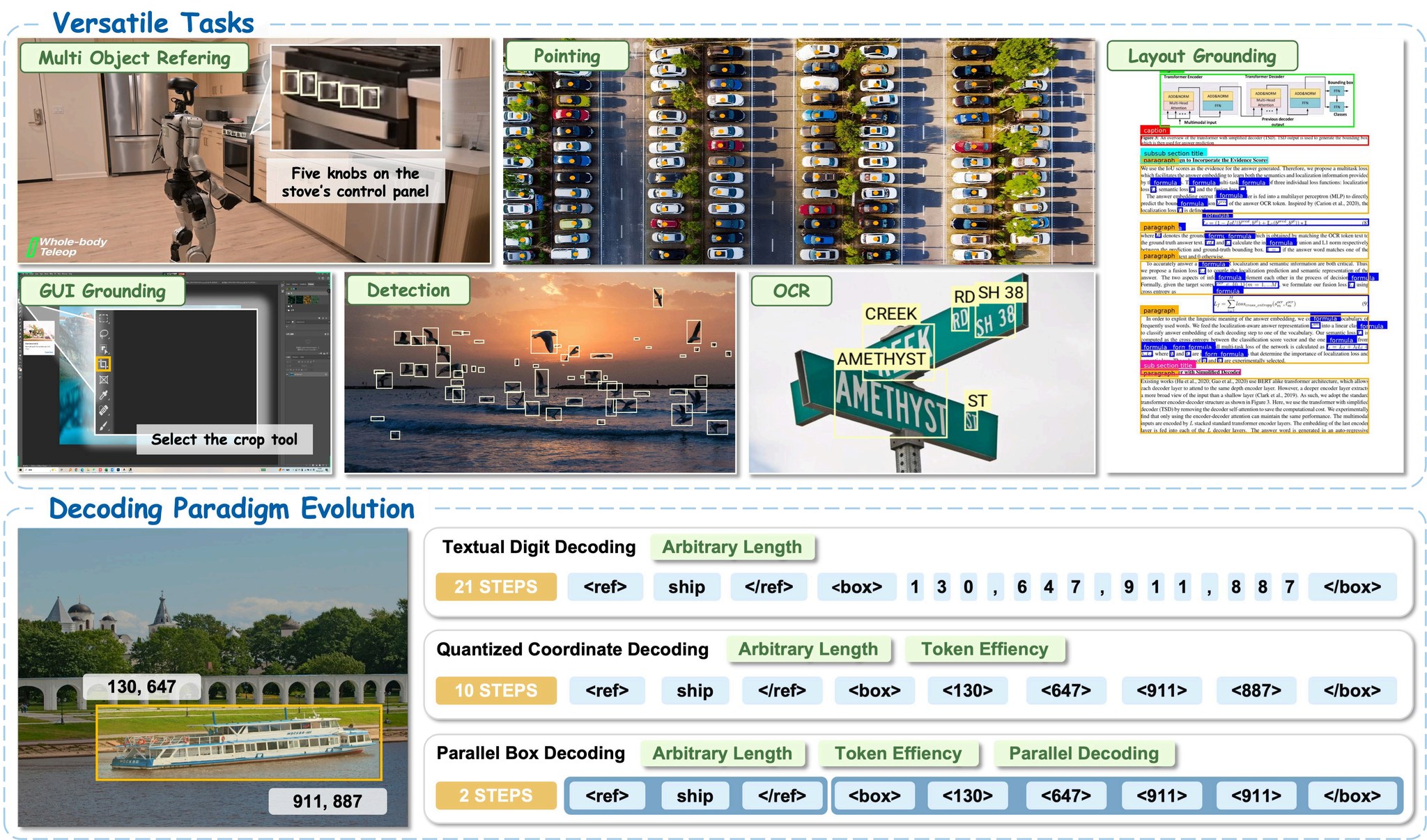 LocateAnything 可在自然场景、机器人、GUI 交互和文档理解等多种领域实现精准的物体定位。
LocateAnything 可在自然场景、机器人、GUI 交互和文档理解等多种领域实现精准的物体定位。
模型概览
LocateAnything 是一款通用视觉语言定位模型,属于 NVIDIA Eagle VLM 模型系列。它支持多种定位使用例:
- 指代表达式定位:根据自然语言描述定位物体
- 开放集物体检测:检测常见及长尾物体类别
- GUI 元素定位:为智能体系统定位 UI 元素
- 文档布局定位:OCR 及文本定位
- 基于点的定位:通过指向进行细粒度空间推理
该模型已集成到 NVIDIA 的 Nemotron 和 Cosmos 产品线中,为计算机使用和视觉定位功能提供支持。
核心创新:并行框解码(PBD)
传统的视觉定位模型以自回归方式逐词生成边界框坐标。LocateAnything 引入了 并行框解码:
- 在 并行的结构化单元 中预测完整的边界框(
x1, y1, x2, y2)和点 - 采用逐块多令牌预测框架
- 在不牺牲几何一致性的前提下实现 2.5 倍吞吐量提升
- 支持 三种推理模式:
- 快速模式:并行解码,追求最大速度
- 慢速模式:自回归解码,追求最高精度
- 混合模式(默认):并行解码,当格式异常时回退到自回归解码
技术架构
| 组件 | 详情 |
|---|---|
| 架构 | 基于 Transformer 的 VLM |
| 视觉编码器 | MoonViT(原生分辨率,最高 2.5K) |
| 语言模型 | Qwen2.5-3B-Instruct |
| 多模态投影器 | MLP 投影器 |
| 总参数 | 3B |
| 最大图像分辨率 | 2.5K(生产环境),批推理可达 4K |
| 最大序列长度 | 25,600 令牌(训练),8,192 个生成令牌(推理) |
| 输出格式 | 基于块:语义块、边界框块、负面块和结束块 |
训练数据
- 1200 万张独立图像,1.38 亿+ 查询,7.85 亿+ 边界框
- 多领域:自然场景、机器人、驾驶、GUI、文档
- 混合数据来源:人工标注、开源数据、模型辅助合成标注
性能表现
LocateAnything 在多个定位基准上表现出色,包括用于开放集检测的 COCO/LVIS、用于 GUI 定位的 ScreenSpot-Pro,以及各种文档布局理解基准。
推理效率
使用 la_flash 注意力后端进行批混合推理:
| 后端 | 时间(4K 探测) | 峰值内存 |
|---|---|---|
| SDPA(密集掩码) | 8.26 秒 | 35.12 GB |
| la_flash(FlashAttention) | 8.03 秒 | 11.71 GB |
开源与获取
LocateAnything-3B 采用 NVIDIA 许可证 发布,仅限非商业研究与开发使用:
- HuggingFace 模型:nvidia/LocateAnything-3B
- GitHub 代码:NVlabs/Eagle/Embodied
- 在线演示:HuggingFace Spaces
- 技术报告:arXiv:2605.27365
- 项目页面:NVIDIA Research
硬件依赖项
针对 NVIDIA GPU(Ampere、Blackwell、Hopper、Lovelace)进行了优化,支持 BF16 精度和 KV 缓存。通过 la_flash 后端进行批推理,可将 A100 上的峰值内存从 35GB 降低至约 12GB。