ByteDance publie USO : Modèle de génération d'images unifié par style et sujet
ByteDance lance le modèle USO, capable de combiner librement n'importe quel sujet avec n'importe quel style tout en maintenant la cohérence du sujet et en obtenant des effets de transfert de style de haute qualité

L'équipe UXO du laboratoire de création intelligente de ByteDance a publié USO (Unified Style and Subject-Driven Generation), un modèle de génération personnalisé qui unifie l'optimisation du style et du sujet. USO peut combiner librement n'importe quel sujet avec n'importe quel style, obtenant des effets de transfert de style de haute qualité tout en maintenant la cohérence du sujet.
Caractéristiques du modèle
Le modèle USO résout le problème des technologies existantes où les tâches de génération pilotées par le style et par le sujet s'opposent l'une à l'autre. Les méthodes traditionnelles traitent généralement ces deux tâches comme des tâches indépendantes : la génération pilotée par le style privilégie la similarité de style, tandis que la génération pilotée par le sujet met l'accent sur la cohérence du sujet, entraînant une relation antagoniste évidente entre les deux.
USO résout ce problème grâce à un cadre unifié, avec le découplage et la recombinaison du contenu et du style comme objectif central. Le modèle adopte une méthode d'entraînement en deux étapes :
Première étape : Aligner les embeddings SigLIP par entraînement d'alignement de style pour obtenir un modèle doté de capacités de style Deuxième étape : Découpler l'encodeur conditionnel et entraîner sur des données triple pour réaliser une génération conditionnelle conjointe
Fonctions principales
Le modèle USO prend en charge plusieurs modes de génération, permettant de combiner librement n'importe quel sujet avec n'importe quel style :
Génération pilotée par le sujet
Maintient la cohérence de l'identité du sujet, adapté à la stylisation de sujets spécifiques tels que les personnes et les objets. Les utilisateurs peuvent fournir une image de référence contenant un sujet spécifique, et le modèle conservera les caractéristiques d'identité du sujet tout en appliquant de nouveaux styles ou scènes.
Génération pilotée par l'identité
Effectue une stylisation tout en maintenant les caractéristiques d'identité. Ce mode est particulièrement adapté à la stylisation de portraits, car il peut maintenir les caractéristiques faciales, les expressions et les informations d'identité tout en changeant les styles artistiques, les vêtements ou les environnements d'arrière-plan.
Génération pilotée par le style
Réalise un transfert de style de haute qualité en appliquant le style des images de référence à un nouveau contenu. Les utilisateurs peuvent fournir une image de référence de style, et le modèle appliquera ce style artistique au contenu décrit par texte, créant de nouvelles images avec des styles spécifiques.
Génération mixte multi-style
Prend en charge l'application de fusion de plusieurs styles. Les utilisateurs peuvent simultanément fournir plusieurs images de référence avec différents styles, et le modèle fusionnera ces éléments de style ensemble pour créer des effets de style mixte uniques.
Génération conjointe style-sujet
Contrôle simultanément le sujet et le style pour réaliser des expressions créatives complexes. Ce mode combine les avantages de la génération pilotée par le sujet et par le style, permettant aux utilisateurs de spécifier des sujets spécifiques et de contrôler les styles artistiques pour un contrôle créatif plus précis.
Principe de fonctionnement
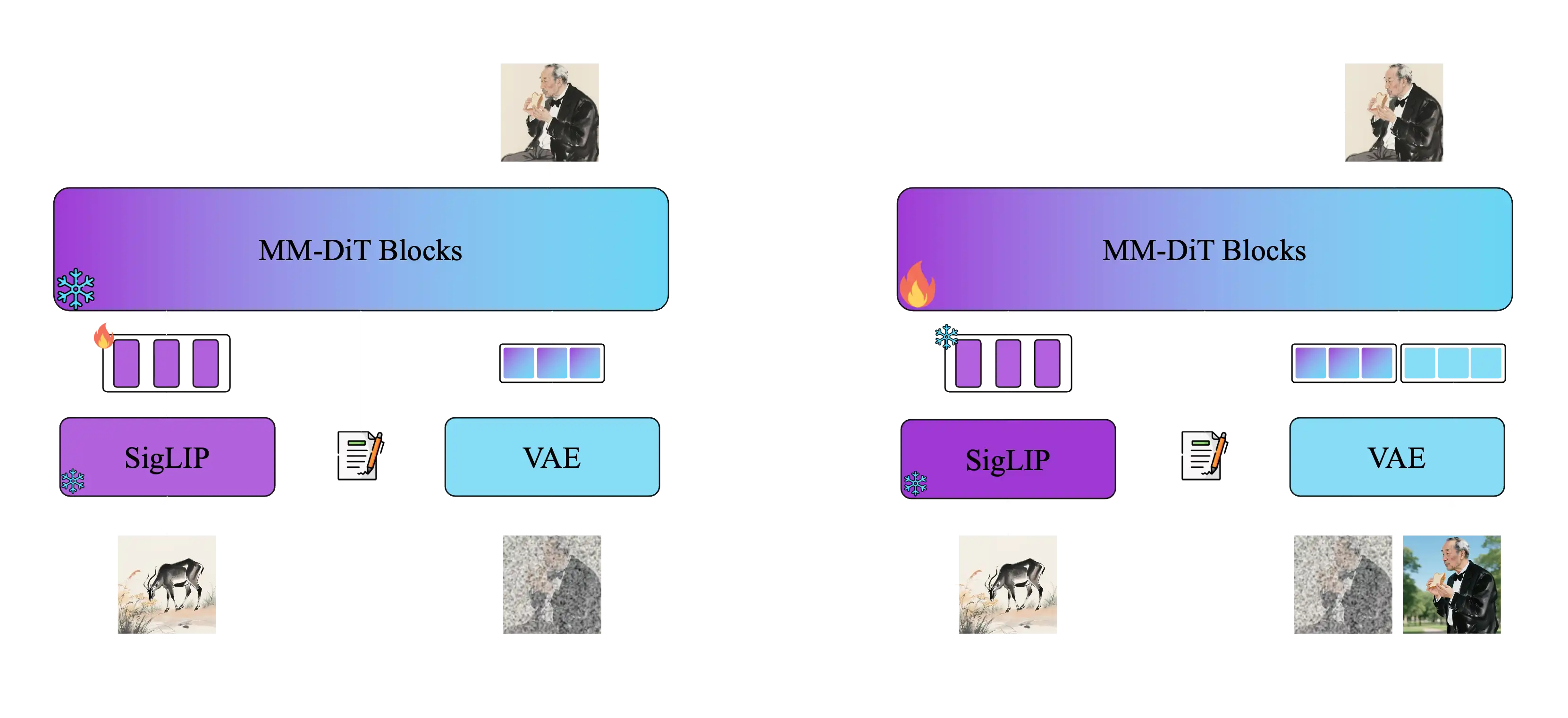
USO adopte une méthode d'entraînement en deux étapes : la première étape aligne les embeddings SigLIP par entraînement d'alignement de style pour obtenir un modèle doté de capacités de style ; la deuxième étape découple l'encodeur conditionnel et entraîne sur des données triple pour réaliser une génération conditionnelle conjointe. Enfin, le paradigme d'apprentissage par récompense de style supervise les deux étapes pour obtenir un modèle unifié plus puissant.
Comparaison avec d'autres méthodes
Comparaison de génération pilotée par le sujet

Comparaison de génération pilotée par le style

Comparaison de génération pilotée par l'identité

Comparaison de génération conjointe style-sujet

Jeu de données et entraînement
L'équipe de recherche a construit un jeu de données triple à grande échelle contenant des images de contenu, des images de style et leurs images de contenu stylisées correspondantes. Grâce à un schéma d'apprentissage par découplage, le modèle peut simultanément traiter deux objectifs : l'alignement de style et le découplage contenu-style.
Performances
Les résultats expérimentaux montrent qu'USO atteint les meilleures performances sur les deux dimensions de cohérence du sujet et de similarité de style parmi les modèles open source. Le modèle peut générer des portraits naturels et non plastiques tout en maintenant une haute cohérence du sujet et une forte fidélité du style.
L'équipe de recherche a également publié le benchmark USO-Bench, qui est le premier benchmark multi-métrique évaluant simultanément la similarité de style et la fidélité du sujet, fournissant un outil d'évaluation standardisé pour les recherches associées.
Open Source et utilisation
Liens du projet :
La publication d'USO apporte de nouvelles solutions au domaine de la génération d'images par IA, particulièrement dans l'équilibre entre le transfert de style et la préservation du sujet. L'open source de ce modèle fera progresser les recherches associées et fournira un soutien d'outils puissant à la communauté open source.
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.