OmniAvatar : Lancement d'un Modèle Efficace de Génération de Vidéos d'Humains Virtuels Contrôlés par Audio
Le modèle OmniAvatar est maintenant open source, permettant la génération de vidéos d'humains virtuels en corps entier contrôlés par audio avec des mouvements naturels et des expressions riches, adapté aux podcasts, aux interactions, aux scènes dynamiques et à diverses applications.
OmniAvatar est un projet open source développé conjointement par l'Université de Zhejiang et le Groupe Alibaba (lancé en juin 2025). C'est un modèle de génération de vidéos d'humains numériques en corps entier contrôlé par audio qui crée des vidéos d'humains virtuels naturelles et fluides à partir d'une seule image de référence, d'une entrée audio et d'indications textuelles. Il prend en charge la synchronisation labiale précise, le contrôle des mouvements du corps entier et l'interaction multi-scènes, marquant une avancée significative dans la technologie des humains numériques.
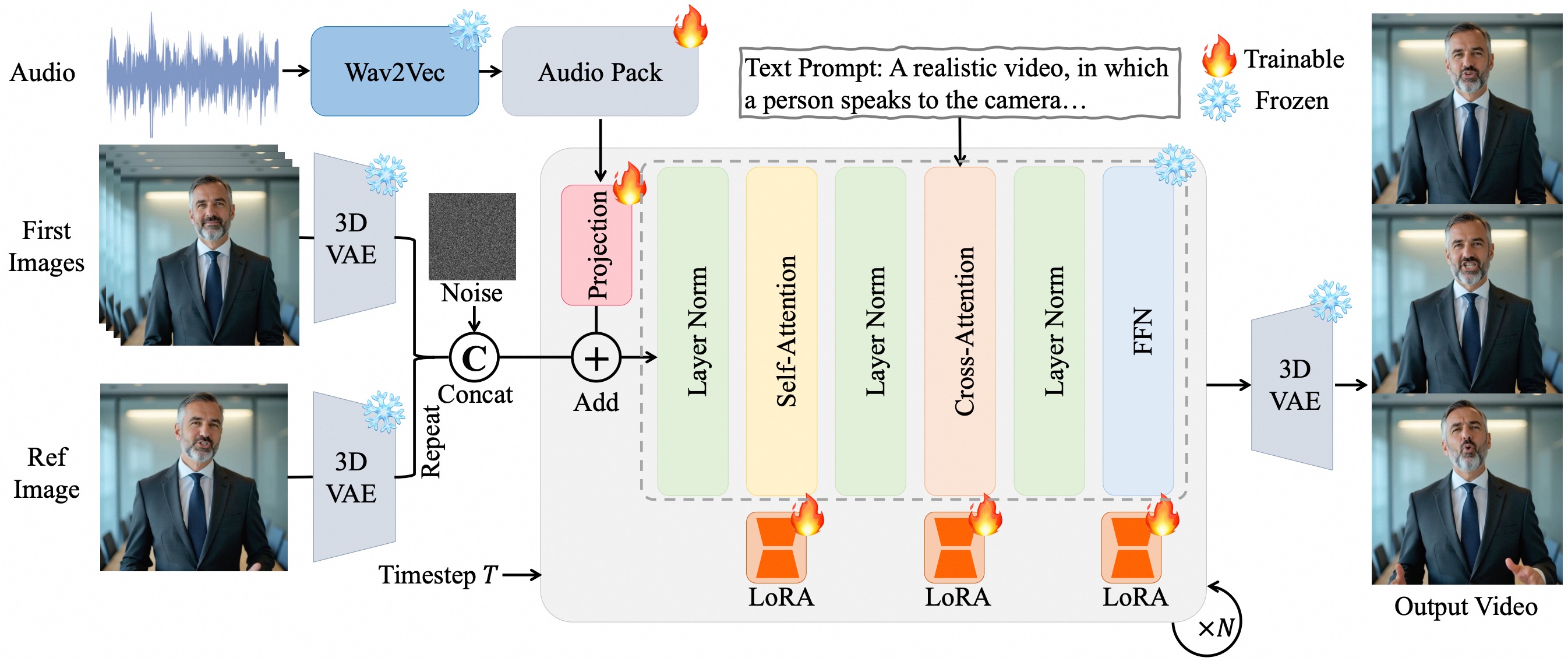
I. Principes Techniques Centraux
Intégration Audio Multicouche au Niveau des Pixels
- Utilise Wav2Vec2 pour extraire les caractéristiques audio, alignant les caractéristiques vocales sur l'espace latent de la vidéo pixel par pixel via le module Audio Pack, intégrant l'information audio à travers de multiples couches temporelles dans le modèle de diffusion (DiT).
- Avantages : Réalise une synchronisation labiale au niveau de l'image (comme les expressions subtiles déclenchées par les mots aspirés) et une coordination des mouvements du corps entier (comme les mouvements d'épaules et les rythmes gestuels), avec une précision de synchronisation supérieure aux modèles conventionnels.
Stratégie de Fine-tuning LoRA
- Insère des matrices d'adaptation de bas rang (LoRA) dans les couches d'attention du Transformer et les couches de réseau feed-forward, ajustant uniquement les paramètres additionnels tout en maintenant les capacités du modèle de base.
- Effets : Prévient le surapprentissage, améliore la stabilité de l'alignement audio-vidéo et permet un contrôle détaillé via des indications textuelles (comme l'amplitude des gestes et l'expression émotionnelle).
Mécanisme de Génération de Longues Vidéos
- Incorpore un encodage latent d'image de référence comme ancres d'identité, combiné à une stratégie de chevauchement d'images et des algorithmes de génération progressive pour atténuer les problèmes de dérive de couleur et d'incohérence d'identité dans les longues vidéos.
II. Caractéristiques Principales et Innovations
Génération de Mouvements Corps Entier
- Dépasse la limitation traditionnelle du "mouvement tête seule", générant des mouvements corporels naturels et coordonnés (comme saluer, trinquer, danser).
Capacités de Contrôle Multimodal
- Contrôle par Indications Textuelles : Ajuste précisément les actions (comme "célébration en trinquant"), les arrière-plans (comme "studio en direct étoilé") et les émotions (comme "joie/colère") via des descriptions.
- Interaction avec les Objets : Prend en charge l'interaction de l'humain virtuel avec les objets de la scène (comme les démonstrations de produits), améliorant le réalisme dans le marketing e-commerce.
Support Multilingue et Vidéos Longues
- Prend en charge l'adaptation de la synchronisation labiale pour 31 langues incluant le chinois, l'anglais et le japonais, capable de générer des vidéos cohérentes de plus de 10 secondes (nécessite des dispositifs avec une VRAM élevée).
III. Riches Démonstrations Vidéo
Le site web officiel d'OmniAvatar fournit de nombreuses démonstrations réelles couvrant divers scénarios et capacités de contrôle. Voici des vidéos sélectionnées :
1. Mouvement et Expressions Corps Entier du Présentateur
2. Actions Diverses et Expressions Émotionnelles
3. Interaction Humain-Objet
4. Contrôle d'Arrière-plan et de Scène
5. Expression Émotionnelle
6. Scénarios de Podcast et Chant
Pour plus de démonstrations, visitez le Site Web Officiel d'OmniAvatar
IV. Open Source et Écosystème
- Dépôt Open Source : GitHub - OmniAvatar
- Téléchargement du Modèle : HuggingFace - OmniAvatar-14B
- Article de Recherche : arXiv:2506.18866
Contenu référencé du Site Web Officiel d'OmniAvatar, GitHub, et matériaux open source associés.