Sortie de XVerse : Un modèle de génération d'images à haute cohérence avec contrôle d'identité multi-sujets et d'attributs sémantiques
ByteDance open-source le modèle XVerse, permettant un contrôle précis et indépendant de plusieurs identités de sujets et d'attributs sémantiques (comme la pose, le style, l'éclairage), améliorant les capacités de personnalisation et de scènes complexes de la génération d'images par IA.
XVerse est un modèle de génération d'images multi-sujets contrôlable open-sourcé par l'équipe Creative AI de ByteDance en 2025. Il se concentre sur la résolution du défi du contrôle précis et indépendant de multiples objets (comme les personnes, les animaux, les objets) dans les images générées par IA. Le modèle prend en charge l'ajustement fin et non interférent de l'identité, de la pose, du style, de l'éclairage et d'autres attributs pour plusieurs sujets dans une image, améliorant significativement les capacités de génération pour les scènes personnalisées et complexes.

I. Capacités fondamentales et innovations
- Contrôle multi-sujets indépendant : Contrôle précis de l'identité, des actions et du style de plusieurs sujets simultanément, évitant le problème courant d'"enchevêtrement d'attributs" des méthodes traditionnelles.
- Haute fidélité et préservation des détails : Préserve les détails comme les mèches de cheveux et les textures grâce à l'encodage des caractéristiques d'image VAE, réduisant les artefacts et la distorsion.
- Édition flexible des attributs sémantiques : Prend en charge l'ajustement flexible des attributs non-identitaires comme l'éclairage et le style artistique, maintenant les caractéristiques du sujet pendant les transitions de scène.
- Haute cohérence et stabilité : Mécanisme innovant de modulation du flux de texte et double régularisation (perte de protection de région, perte d'attention texte-image) assurant la stabilité et la cohérence de la génération.
II. Aperçu des principes techniques
1. Mécanisme de modulation du flux de texte (Adaptateur T-Mod)
- Convertit les images de référence en décalages d'embedding de texte, réalisant un contrôle précis et indépendant de plusieurs sujets grâce à des signaux de contrôle en couches (partage global + modulation par blocs).
- L'adaptateur T-Mod intègre les caractéristiques d'image CLIP avec les prompts textuels, générant des signaux de cross-modulation pour éviter la confusion des caractéristiques.
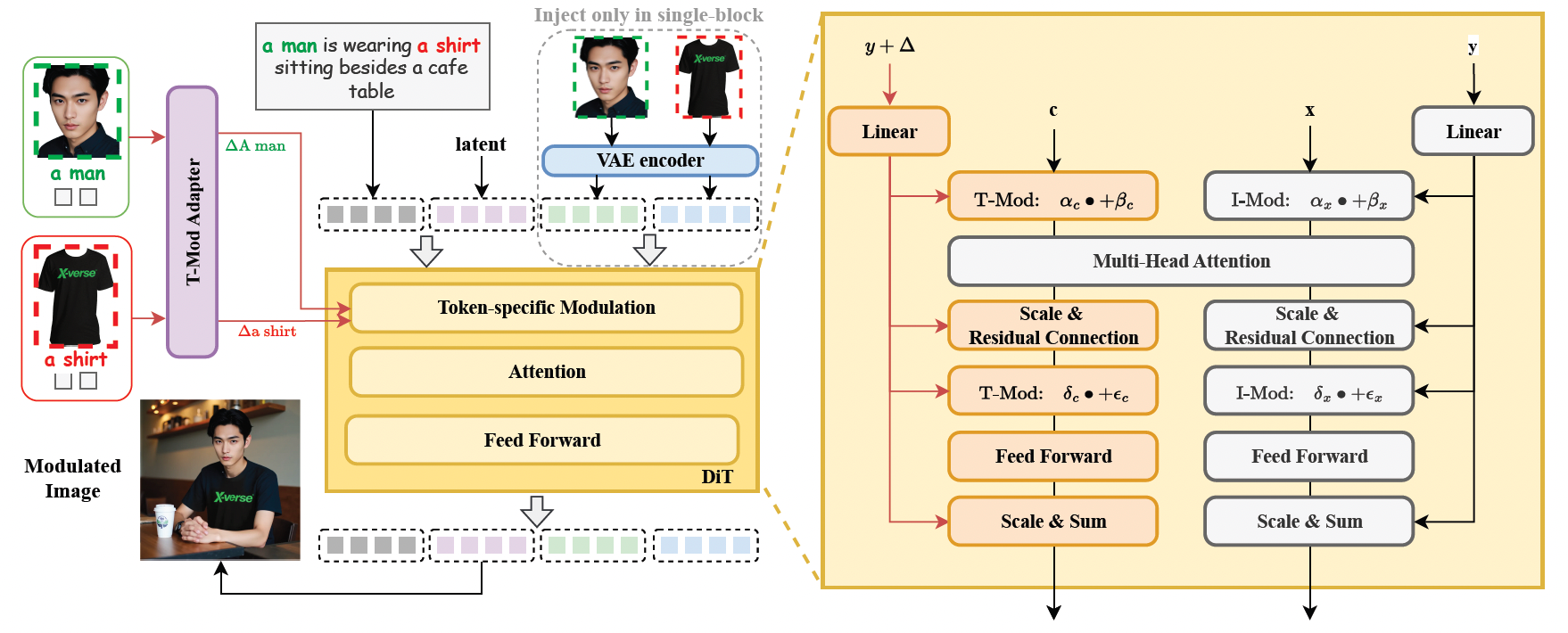
2. Module d'encodage des caractéristiques d'image VAE
- Introduit des caractéristiques encodées VAE dans la structure FLUX pour améliorer la préservation des détails, rendant les images générées plus réalistes et naturelles.
3. Mécanisme de double régularisation
- Perte de protection de région : Préserve aléatoirement certaines régions de la modulation pour s'assurer que les objets non ciblés restent non perturbés.
- Perte d'attention texte-image : Optimise l'allocation de l'attention pour améliorer la précision de l'alignement sémantique.
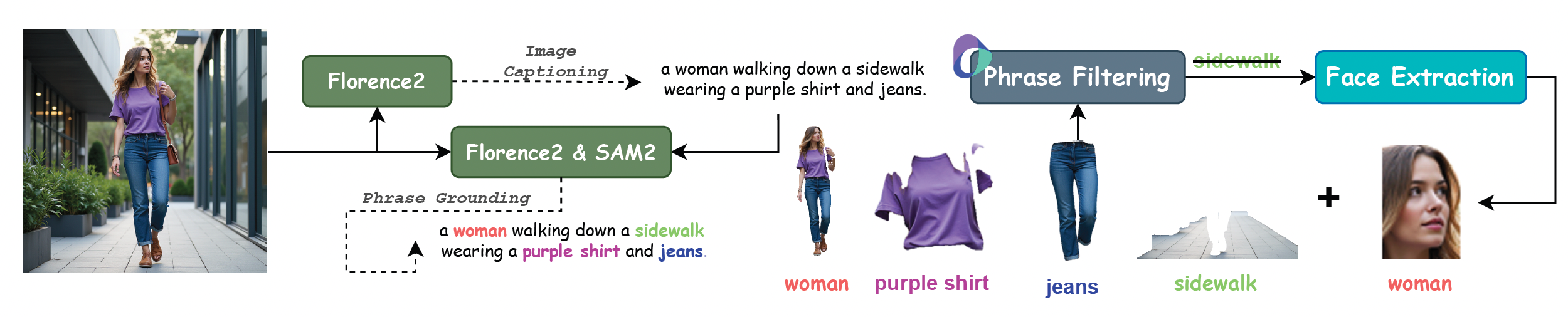
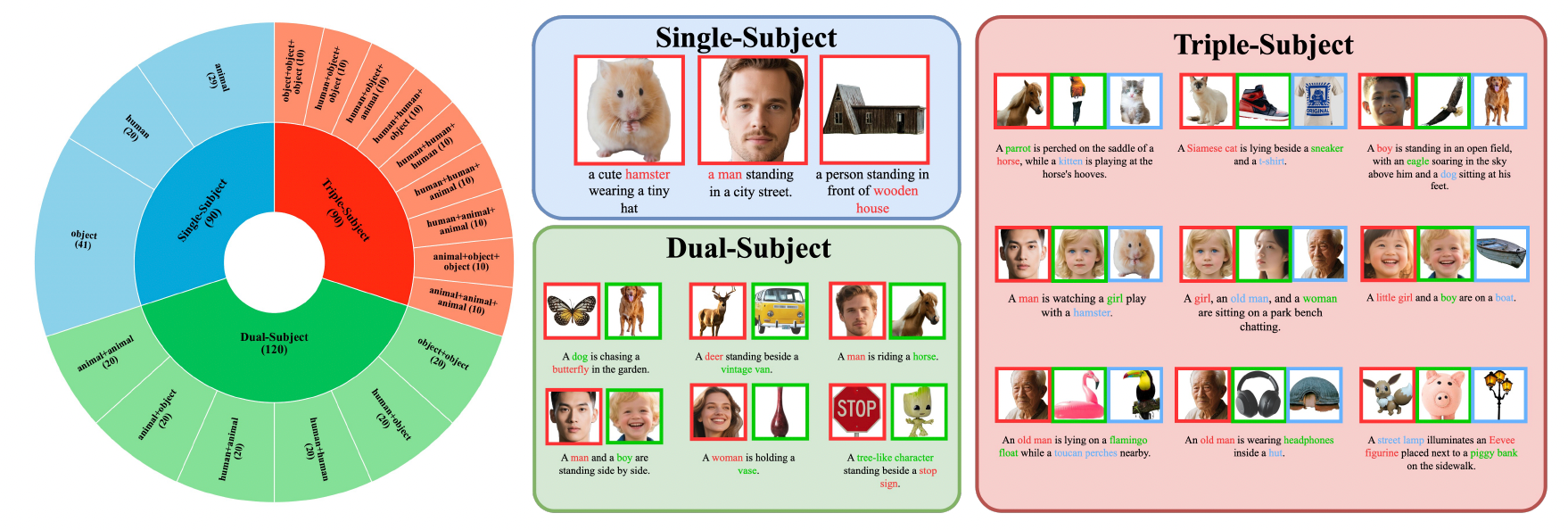
III. Données d'entraînement et benchmarks d'évaluation
XVerse utilise un dataset de contrôle multi-sujets de haute qualité couvrant 20 types de personnes, 74 types d'objets et 45 types d'animaux, synthétisant des millions d'images de haute qualité esthétique.
Les performances du modèle surpassent significativement les méthodes similaires sur le benchmark XVerseBench, supportant divers scénarios de contrôle incluant un, deux et trois sujets.
| Métrique | Signification | | | | | Score DPG | Capacité d'édition | | Similarité ID visage | Cohérence de l'identité de la personne | | Similarité DINOv2 | Cohérence des caractéristiques d'objet | | Score esthétique | Qualité esthétique de l'image |
IV. Résultats expérimentaux et études de cas
1. Contrôle précis de l'identité et des attributs d'un sujet unique
XVerse maintient la cohérence de l'identité du sujet à travers divers scénarios tout en ajustant de manière flexible la pose, les vêtements, l'environnement et d'autres attributs.





2. Cohérence multi-sujets et contrôle indépendant
XVerse réalise un contrôle indépendant des identités et attributs de plusieurs sujets au sein de la même image tout en maintenant une interaction naturelle et une cohérence de scène.





3. Contrôle flexible des attributs sémantiques
XVerse prend en charge l'ajustement détaillé des attributs sémantiques comme l'éclairage, la pose et le style pour répondre à divers besoins créatifs.

V. Open Source et ressources associées
- Page du projet : https://bytedance.github.io/XVerse/
- Dépôt GitHub : https://github.com/bytedance/XVerse
- Téléchargement du modèle : https://huggingface.co/ByteDance/XVerse
- Article technique : https://arxiv.org/abs/2506.21416
Contenu référencé depuis la page officielle XVerse, GitHub, et les documents open-source associés.
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.