Pixel-Reasoner : Publication du modèle open source de raisonnement visuel au niveau du pixel
Pixel-Reasoner, basé sur Qwen2, offre des capacités de compréhension et de raisonnement visuel au niveau du pixel, à la fois globales et locales, prend en charge l'analyse détaillée par zoom et fait progresser les modèles de langage visuel.
Pixel-Reasoner est un modèle de langage visuel open source basé sur Qwen2, axé sur l'amélioration de la compréhension et du raisonnement visuel au niveau du pixel. Le modèle peut analyser une image dans son ensemble et permet également de zoomer sur des zones locales pour une observation détaillée, ce qui aide à capturer les détails fins des images.
Principales caractéristiques
- Raisonnement au niveau du pixel : Pixel-Reasoner peut raisonner directement dans l'espace des pixels de l'image, sans se limiter au raisonnement textuel traditionnel.
- Combinaison de la compréhension globale et locale : Le modèle peut saisir le contenu général d'une image et aussi "zoomer" pour se concentrer sur des zones spécifiques pour une analyse plus fine.
- Entraînement guidé par la curiosité : Grâce à un mécanisme de récompense basé sur la curiosité, le modèle est encouragé à explorer et à utiliser activement les opérations au niveau du pixel, améliorant ainsi la diversité et la précision du raisonnement visuel.
- Open source disponible : Le modèle, les jeux de données et le code associé sont tous open source, ce qui facilite leur téléchargement et leur essai par la communauté.
Un nouveau paradigme pour le raisonnement au niveau du pixel
Pixel-Reasoner introduit le concept de "Raisonnement dans l'espace pixel". Contrairement aux modèles de langage visuel traditionnels qui reposent uniquement sur le raisonnement textuel, Pixel-Reasoner peut analyser et opérer directement au niveau des pixels de l'image.
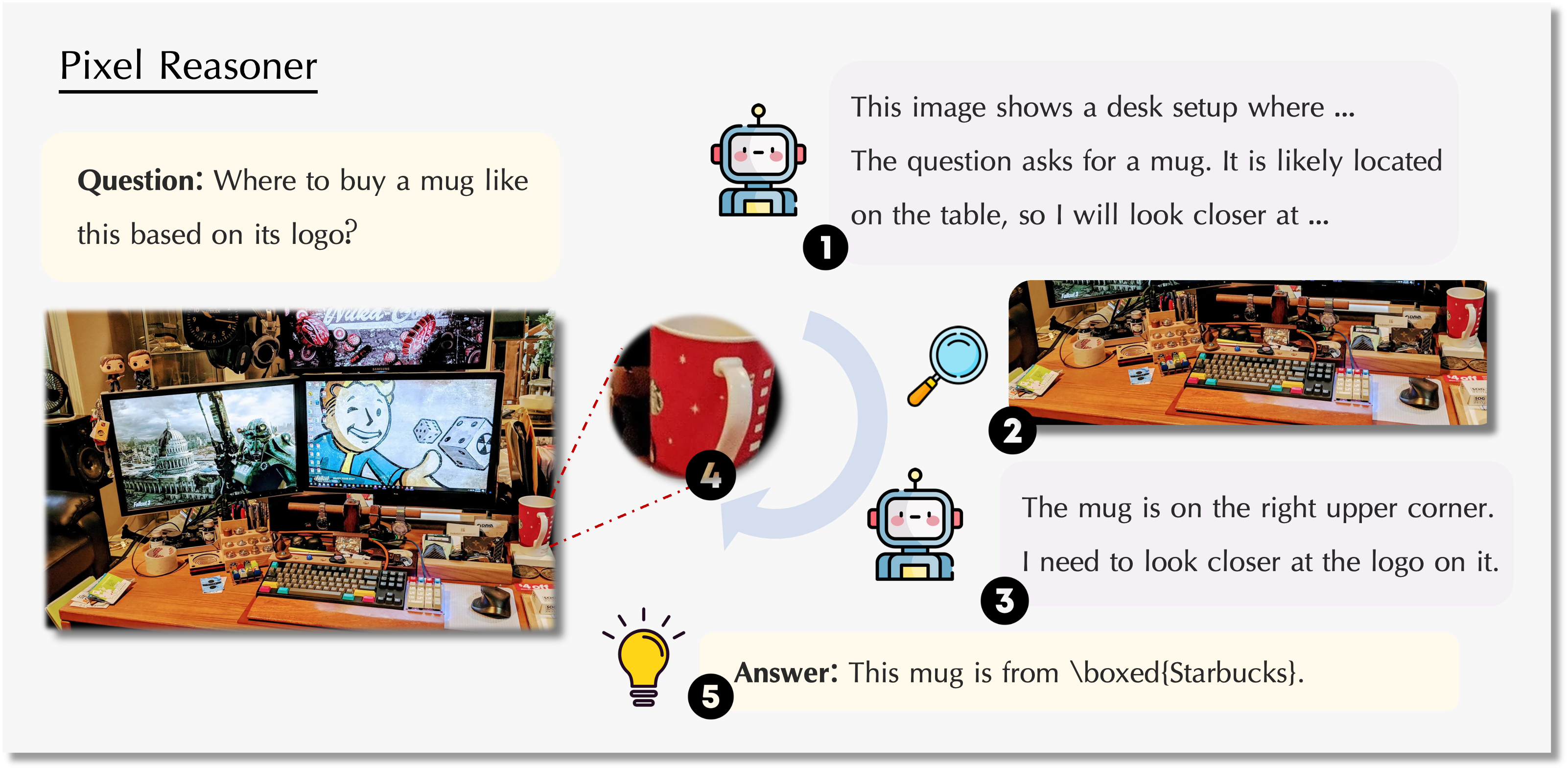 Comme illustré ci-dessus, le modèle peut comprendre l'image dans son ensemble et aussi zoomer ou sélectionner des zones pour se concentrer sur les détails, améliorant ainsi sa capacité à comprendre des contenus visuels complexes.
Comme illustré ci-dessus, le modèle peut comprendre l'image dans son ensemble et aussi zoomer ou sélectionner des zones pour se concentrer sur les détails, améliorant ainsi sa capacité à comprendre des contenus visuels complexes.
Défis d'entraînement et mécanismes innovants
Lors de l'entraînement, l'équipe a constaté que les modèles de langage visuel existants rencontrent un "piège d'apprentissage" dans le raisonnement au niveau du pixel : ils sont meilleurs en raisonnement textuel et ont tendance à échouer dans les opérations au niveau du pixel, manquant de motivation pour explorer les actions visuelles.
 L'image ci-dessus montre le goulot d'étranglement rencontré lors des premières étapes du raisonnement dans l'espace pixel : en raison de capacités initiales limitées, le modèle a tendance à éviter les opérations visuelles, ce qui affecte le développement des compétences de raisonnement au niveau du pixel.
L'image ci-dessus montre le goulot d'étranglement rencontré lors des premières étapes du raisonnement dans l'espace pixel : en raison de capacités initiales limitées, le modèle a tendance à éviter les opérations visuelles, ce qui affecte le développement des compétences de raisonnement au niveau du pixel.
Pour y remédier, Pixel-Reasoner utilise un mécanisme d'apprentissage par renforcement guidé par la curiosité, récompensant le modèle pour avoir tenté activement des opérations au niveau du pixel et améliorant progressivement ses capacités de raisonnement dans l'espace visuel.
Synthèse des données et processus d'entraînement
L'entraînement de Pixel-Reasoner se divise en deux étapes :
- Ajustement par instructions : Des trajectoires de raisonnement synthétiques avec des opérations visuelles aident le modèle à se familiariser avec diverses actions au niveau du pixel.
- Apprentissage par renforcement guidé par la curiosité : Un mécanisme de récompense encourage le modèle à explorer et à utiliser activement les opérations visuelles lors du raisonnement.
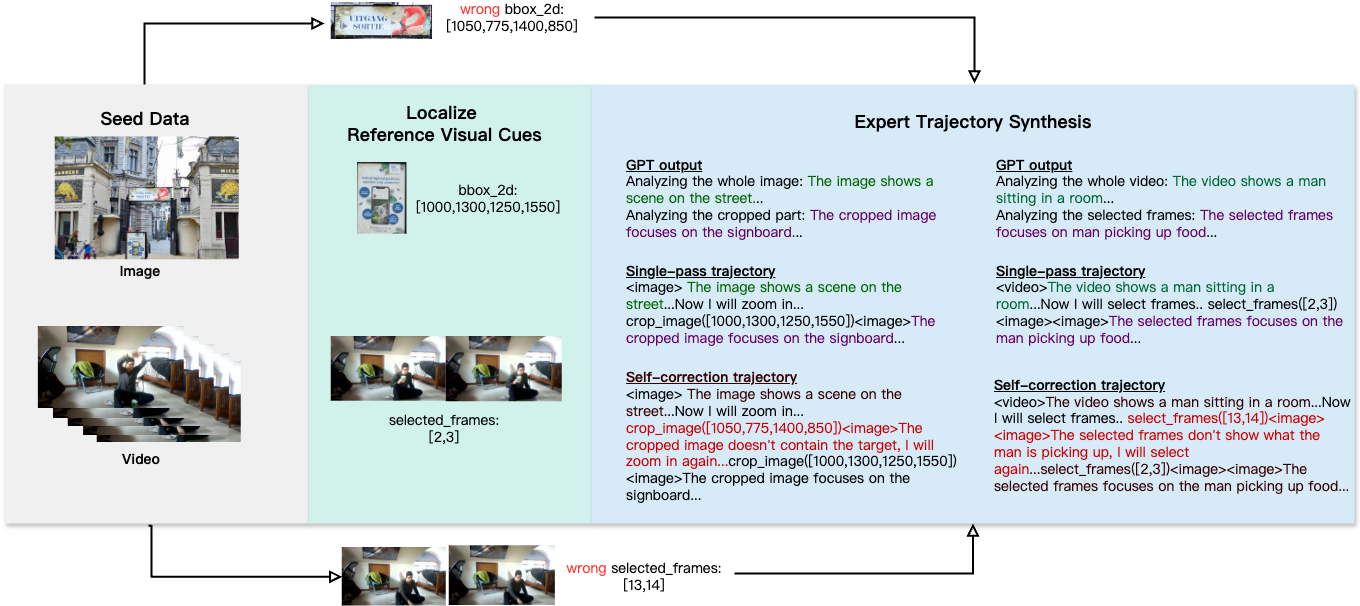 Comme illustré ci-dessus, l'équipe utilise des images et des vidéos haute résolution, combinées à des annotations automatiques et manuelles, pour générer des données de raisonnement variées, aidant le modèle à apprendre à analyser et à s'auto-corriger dans l'espace visuel.
Comme illustré ci-dessus, l'équipe utilise des images et des vidéos haute résolution, combinées à des annotations automatiques et manuelles, pour générer des données de raisonnement variées, aidant le modèle à apprendre à analyser et à s'auto-corriger dans l'espace visuel.
Scénarios d'application typiques
Pixel-Reasoner est particulièrement adapté pour :
- Les tâches nécessitant l'identification de petits objets ou de détails dans les images
- La compréhension d'informations multi-régions et multi-niveaux dans des images ou des vidéos complexes
- Les tâches de raisonnement visuel combinant des informations globales et locales
Scénarios d'application
Pixel-Reasoner est idéal pour les scénarios nécessitant une compréhension visuelle détaillée, tels que :
- L'analyse de contenus complexes d'images ou de vidéos
- La reconnaissance de petits objets, de relations subtiles ou de textes intégrés
- Les tâches visuelles combinant des informations globales et locales
Liens connexes
- Article : https://arxiv.org/abs/2505.15966
- Page officielle : https://tiger-ai-lab.github.io/Pixel-Reasoner/
- Modèle HuggingFace : https://huggingface.co/TIGER-Lab/PixelReasoner-RL-v1
- Démo en ligne : https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
Le contenu de cet article est basé sur les documents et publications officiels de Pixel-Reasoner.
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.