Sand AI publie MAGI-1 : Génération vidéo autorégressive à grande échelle
Sand AI a rendu open-source MAGI-1, un modèle autorégressif qui génère des vidéos par segments, proposant des versions à 24B et 4,5B de paramètres et prenant en charge plusieurs modes de génération vidéo
L'équipe de Sand AI a officiellement rendu open-source le modèle de génération vidéo MAGI-1 le 21 avril, avec des plans pour publier une version à 4,5 milliards de paramètres d'ici la fin avril. Il s'agit d'un modèle mondial capable de prédire des séquences de segments vidéo de manière autorégressive, prenant en charge les méthodes de génération Texte-vers-Vidéo (T2V), Image-vers-Vidéo (I2V) et Vidéo-vers-Vidéo (V2V).
Innovations techniques
MAGI-1 emploie de multiples innovations techniques qui lui confèrent des avantages uniques dans le domaine de la génération vidéo :
VAE basé sur Transformer
- Utilise un auto-encodeur variationnel basé sur Transformer avec une compression spatiale 8x et temporelle 4x
- Offre le temps de décodage moyen le plus rapide tout en maintenant une reconstruction de haute qualité
Algorithme de débruitage autorégressif
MAGI-1 génère des vidéos de manière autorégressive, segment par segment, plutôt qu'en une seule fois. Chaque segment (24 images) est débruité de manière holistique, et la génération du segment suivant commence dès que le segment actuel atteint un certain niveau de débruitage. Cette conception permet le traitement simultané de jusqu'à quatre segments pour une génération vidéo efficace.

Architecture du modèle de diffusion
MAGI-1 est construit sur le Transformateur de Diffusion, incorporant plusieurs innovations clés pour améliorer l'efficacité de l'entraînement et la stabilité à grande échelle. Ces avancées comprennent l'Attention Causale par Blocs, le Bloc d'Attention Parallèle, QK-Norm et GQA, la Normalisation Sandwich dans FFN, SwiGLU et la Modulation Softcap.
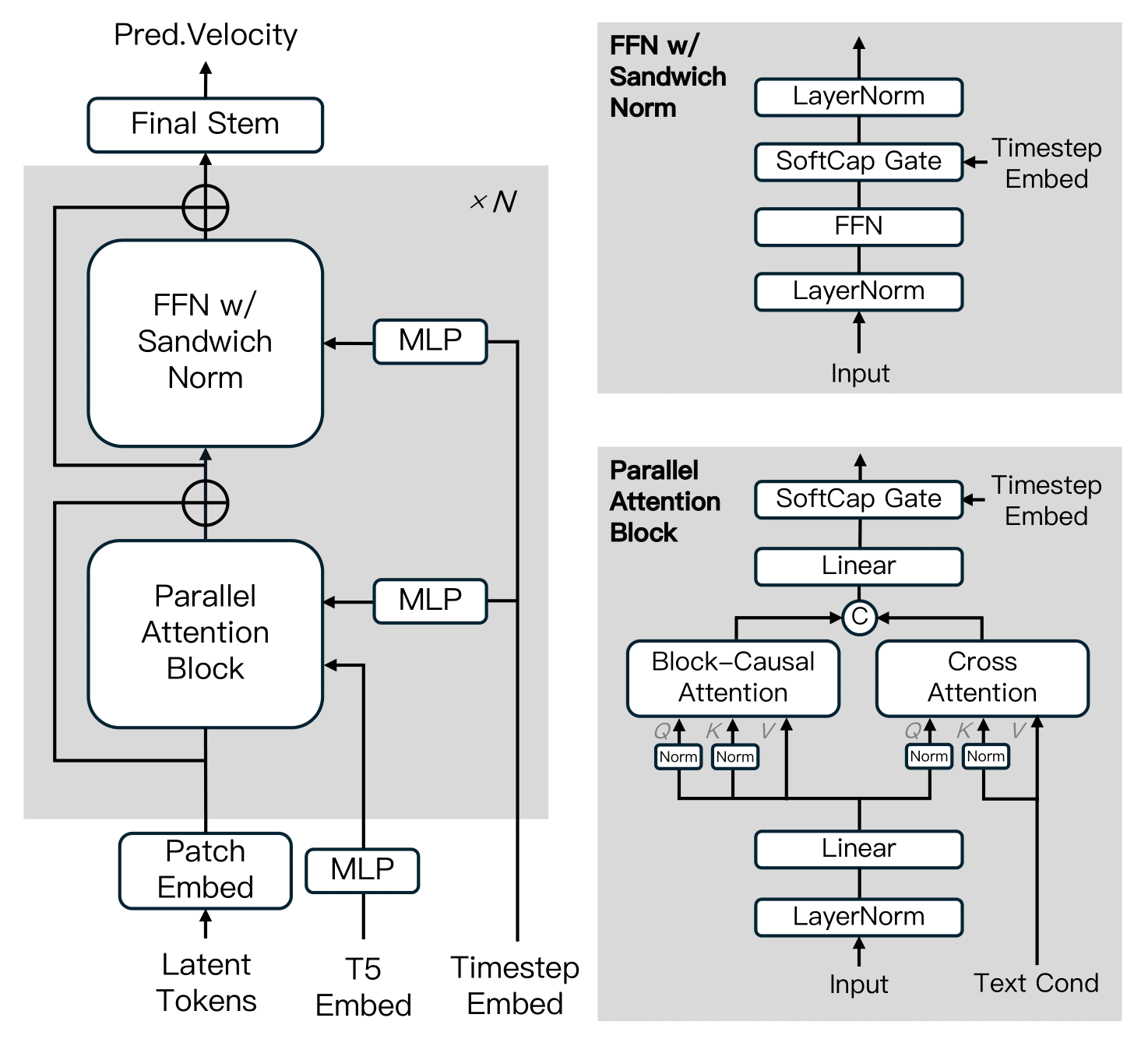
Algorithme de distillation
Le modèle adopte une approche de distillation par raccourci qui entraîne un modèle unique basé sur la vélocité pour prendre en charge des budgets d'inférence variables. En imposant une contrainte d'auto-cohérence — équivalant un grand pas à deux pas plus petits — le modèle apprend à approximer des trajectoires de correspondance de flux à travers plusieurs tailles de pas. Pendant l'entraînement, les tailles de pas sont échantillonnées cycliquement parmi 64, 32, 16, 8, et la distillation de guidage sans classificateur est incorporée pour préserver l'alignement conditionnel. Cela permet une inférence efficace avec une perte minimale de fidélité.
Versions du modèle
Sand AI fournit des poids pré-entraînés pour plusieurs versions de MAGI-1, y compris des modèles de 24B et 4,5B, ainsi que les modèles distillés et quantifiés correspondants :
| Modèle | Matériel recommandé | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 ou RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
Évaluation des performances
Évaluation physique
Grâce aux avantages naturels de l'architecture autorégressive, MAGI-1 atteint une précision bien supérieure dans la prédiction du comportement physique sur le benchmark Physics-IQ grâce à la continuation vidéo.
Dans le score Physics-IQ, le mode Vidéo-vers-Vidéo (V2V) de MAGI atteint 56,02 points, tandis que son mode Image-vers-Vidéo (I2V) atteint 30,23 points, surpassant significativement d'autres modèles commerciaux open-source et propriétaires tels que VideoPoet, Kling1.6 et Sora.
Comment exécuter
MAGI-1 prend en charge l'exécution via un environnement Docker (recommandé) ou le code source. Les utilisateurs peuvent contrôler de manière flexible l'entrée et la sortie en ajustant les paramètres dans le script run.sh pour répondre à différentes exigences :
--mode: Spécifie le mode d'opération (t2v, i2v ou v2v)--prompt: Le texte utilisé pour la génération vidéo--image_path: Chemin vers le fichier image (utilisé uniquement en mode i2v)--prefix_video_path: Chemin vers le fichier vidéo préfixe (utilisé uniquement en mode v2v)--output_path: Chemin où le fichier vidéo généré sera sauvegardé
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.