TTT-Video : Technologie pour la génération de vidéos longues
Des chercheurs développent le modèle TTT-Video utilisant la technologie Test-Time Training basée sur CogVideoX 5B, capable de générer des vidéos cohérentes jusqu'à 63 secondes
Des chercheurs ont récemment lancé un projet open-source appelé TTT-Video, une technologie qui dépasse les limitations temporelles traditionnelles de la génération vidéo par IA, capable de produire un contenu vidéo cohérent jusqu'à 63 secondes. Cette technologie résout les problèmes de cohérence du contenu dans la génération de vidéos longues grâce à la méthode innovante de Test-Time Training (Entraînement en Temps de Test).
Relever les défis clés de la génération vidéo
Actuellement, la plupart des modèles de génération vidéo par IA ne peuvent créer que des clips vidéo courts de 3 à 5 secondes. Cela est dû au fait que les modèles Transformer utilisés pour la génération vidéo ont des coûts de calcul qui augmentent de façon quadratique lors du traitement de longues séquences en raison de leur mécanisme d'auto-attention, ce qui rend inefficace le traitement de vidéos longues.
TTT-Video résout ce problème de manière innovante : il conserve les couches d'attention du modèle préentraîné original pour l'attention locale sur chaque segment de 3 secondes, tout en introduisant des couches spéciales de Test-Time Training pour gérer les relations à longue distance dans le contexte global.
Implémentation technique
Le projet est basé sur le modèle CogVideoX 5B (un Transformer de diffusion pour la génération de texte vers vidéo) avec des innovations clés comprenant :
- Introduction de couches TTT pour traiter la séquence globale et sa version inversée, combinant les sorties via des connexions résiduelles à portes
- Extension du contexte en entrelaçant chaque segment avec des embeddings de texte et de vidéo
- Entraînement par étapes : d'abord affinage à la durée originale préentraînée de 3 secondes, puis entraînement progressif à des durées vidéo de 9, 18, 30 et 63 secondes
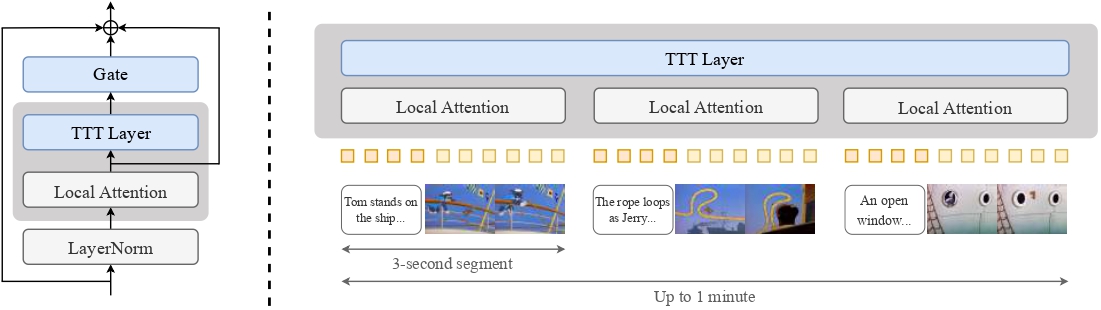
Architecture du modèle TTT-Video : Traitement des séquences globales via des couches TTT combinées à des mécanismes d'attention locale
L'équipe de recherche a utilisé le dessin animé classique "Tom et Jerry" comme cas de test, générant des vidéos animées styliquement cohérentes d'environ une minute, bien que limitées par la taille de 5B paramètres, il y a encore une marge d'amélioration dans la qualité de génération.
Résultats de génération impressionnants
<video style={{ width: '100%', maxWidth: '680px' }} src="https://test-time-training.github.io/video-dit/videos/63s-demo/homeless.mp4" controls />
L'aspect le plus impressionnant de TTT-Video est sa capacité à générer des animations de style "Tom et Jerry" d'une durée allant jusqu'à une minute en un seul passage, avec :
- Aucun besoin d'édition, de raccord ou de post-traitement
- Un contenu entièrement original, avec des scènes qui n'existent pas dans le dessin animé original
- Des actions de personnages, des transitions de scènes et des intrigues cohérentes

Images d'animation générées par TTT-Video dans le style Tom et Jerry
Importance pour les créateurs d'IA
Cette technologie signifie ce qui suit pour les créateurs d'IA utilisant des outils comme ComfyUI :
- Le potentiel pour une génération de vidéos IA plus longues et plus narratives à l'avenir
- Des solutions aux problèmes clés de cohérence dans la génération vidéo
- La possibilité pour les créateurs de créer du contenu vidéo plus long sans avoir à raccorder manuellement plusieurs segments
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.