Sesame présente le modèle vocal CSM pour des conversations naturelles
Sesame dévoile son modèle de conversation vocale CSM basé sur une architecture double Transformer, offrant une interaction en temps réel et un cœur open source
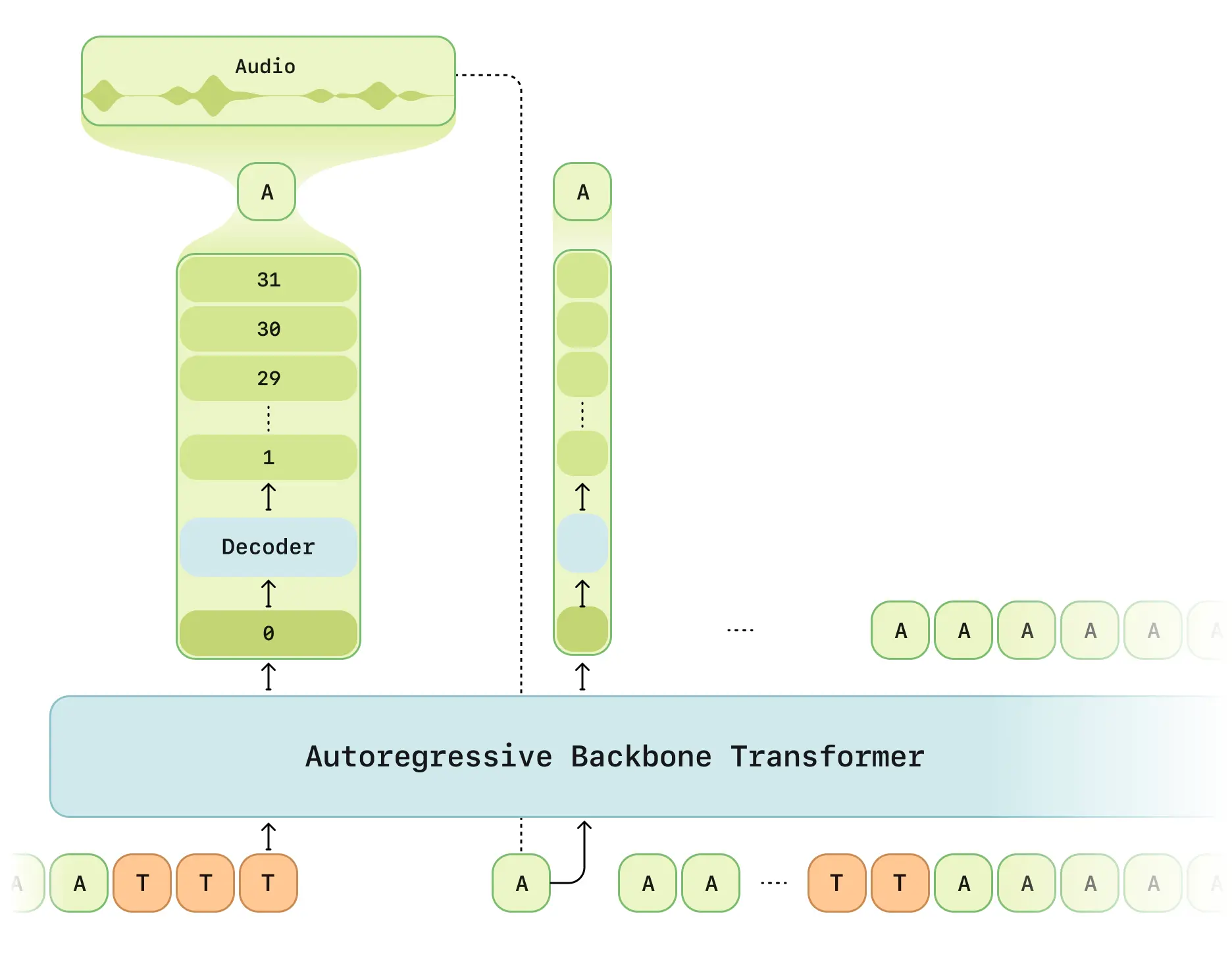
Sesame Research a présenté son modèle de conversation vocale CSM lors d'une démo officielle, démontrant des capacités d'interaction vocale révolutionnaires. L'architecture double Transformer permet des échanges vocaux quasi-humains.
Architecture technique
Caractéristiques clés du CSM :
- Traitement en deux étapes : Réseau principal multimodal (texte/voix) + décodeur audio
- Tokeniseur RVQ : Encodeur de quantification Mimi à 12.5 Hz
- Mode de latence optimisée : Résout les délais de génération RVQ traditionnels
- Calcul distribué : Échantillonnage 1/16 pour l'efficacité
- Structure Llama : Réseau principal basé sur LLaMA
Fonctionnalités principales
- Conscience contextuelle : Mémoire de conversation de 2 minutes (2048 tokens)
- Intelligence émotionnelle : Analyse des émotions via classificateur à 6 couches
- Temps réel : Latence < 500 ms (moyenne 380 ms)
- Multi-locuteurs : Gestion simultanée de plusieurs voix
Spécifications techniques
| Paramètre | Détails | |
|
--| | Données d'entraînement | 1 million d'heures de conversations | | Taille du modèle | 8B backbone + 300M décodeur | | Longueur de séquence | 2048 tokens (~2 minutes) | | Matériel requis | RTX 4090 ou supérieur |
État de l'open source
Repo GitHub contient :
- Livre blanc complet
- Exemples d'API REST
- Kit de prétraitement audio
- Guide de déploiement quantifié
⚠️ Limitations :
- Code d'entraînement non publié (prévu Q3 2025)
- Clé API requise
- Priorité aux scénarios anglophones
Résultats d'évaluation
D'après le rapport officiel :
- Naturalité : Score CMOS équivalent aux enregistrements humains
- Compréhension contextuelle : +37% de précision
- Cohérence phonétique : 95% de stabilité
- Latence : Temps de génération initial réduit de 68%
Sources : Article de recherche|X
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.