\"Alibaba Open Source ACE++ : Génération d'Images Cohérentes de Personnages Sans Entraînement\"
L'Institut de Recherche Alibaba lance l'outil open source ACE++ pour la génération d'images, utilisant une technologie de remplissage de contenu contextuel pour générer de nouvelles images cohérentes de personnages à partir d'une seule entrée, offrant une expérience en ligne et trois modèles spécialisés.
10 février 2025 — L'Institut de Recherche Alibaba annonce officiellement le lancement open source de son nouvel outil d'imagerie IA ACE++. Basé sur des algorithmes innovants de remplissage de contenu contextuel, les utilisateurs peuvent générer de nouvelles images avec des caractéristiques hautement cohérentes des personnages à partir d'une seule image d'entrée, avec support pour l'expérience en ligne et le déploiement local.
Innovations Techniques Principales
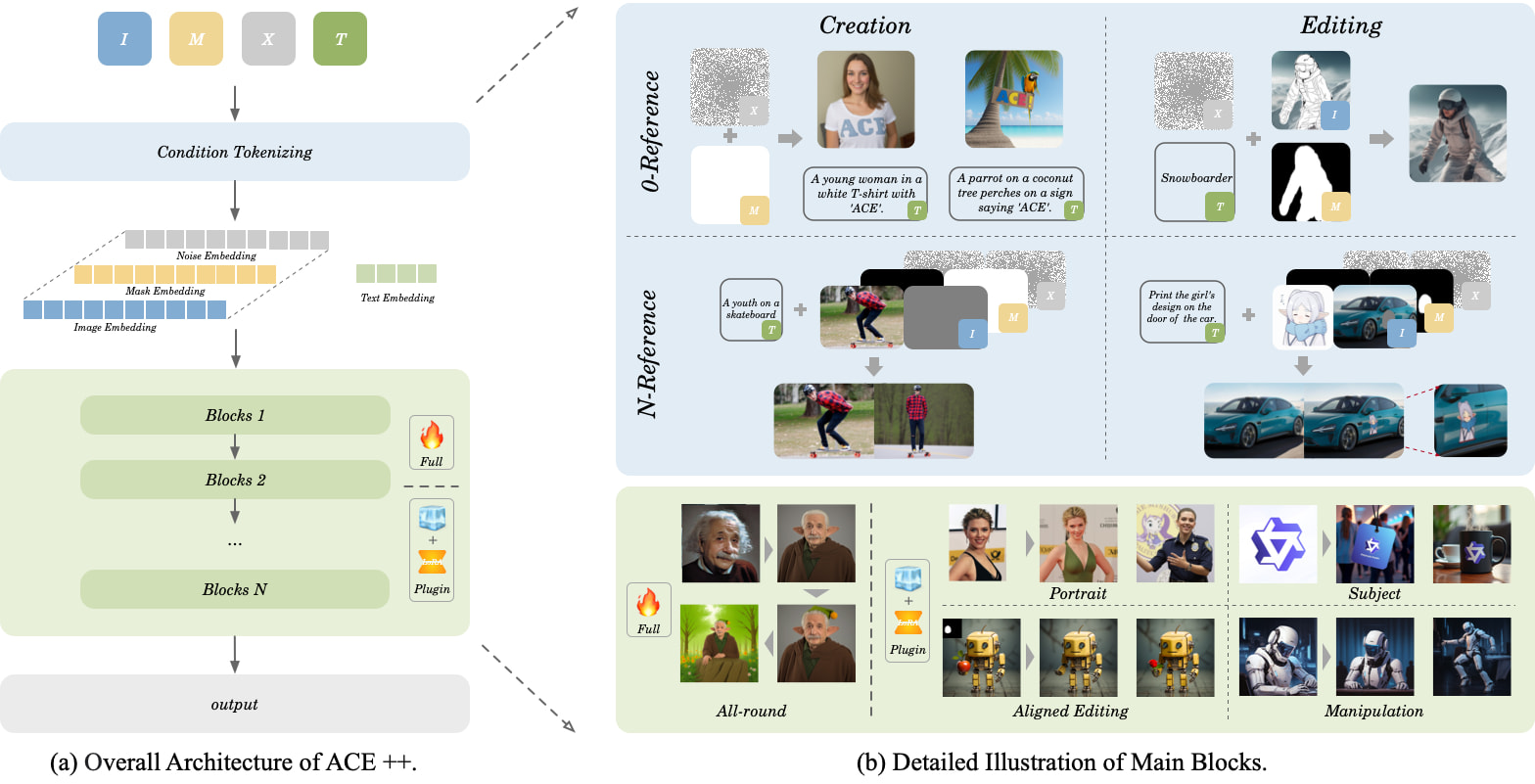
Caractéristiques Clés
- Génération Sans Entraînement : Exploite le modèle de base FLUX.1-Fill-dev, réalisant un déploiement sans entraînement via l'adaptation LoRA
- Édition Multimodale :
- Changement de Tenue des Personnages (supporte les changements de vêtements/coiffure/accessoires)
- Reconstruction de Scènes (remplacement d'arrière-plan/ajout/suppression d'objets)
- Restauration Intelligente (suppression des défauts/amélioration de la qualité)
- Compréhension Sémantique : Peut traiter des instructions composées comme "ajouter de la vapeur à la tasse de café, placer sur une table en bois"
Avancées Techniques
- Unité de Contexte Long (LCU) : Traite simultanément le contenu de l'image, les instructions textuelles et les régions d'édition
- Mécanisme d'Attention Dynamique : Atteint un taux de rétention des caractéristiques de 92,3% en résolution 512×512
- Optimisation en Deux Étapes : Approche d'entraînement pas à pas combinant restauration de base et compétences d'édition spécialisées
Tests de Scénarios d'Application
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
Applications Typiques
-
Changements de Tenue de Modèles Virtuels
- Génère des affichages multi-angles à partir d'images de vêtements plates
- Supporte l'ajustement dynamique du teint/type de corps/scène
-
Conception de Personnages de Film
- Réalise la transformation entre styles (réaliste→Disney/cyberpunk)
- Génération multi-scènes maintenant la continuité des caractéristiques
-
Restauration Intelligente d'Images
- Reconstruction en résolution 4K de vieilles photos
- Suppression parfaite des occlusions complexes
Canaux d'Accès aux Ressources
Entrées Officielles
| Type de Ressource | Lien d'Accès | |
--|
-| | Page du Projet | https://ali-vilab.github.io/ACE_plus_page/ | | Dépôt de Code | GitHub | | Expérience en Ligne | ModelScope |
Liens Officiels de Téléchargement des Modèles
Modèles d'Adaptation Spécialisés
| Type de Modèle | Nom de Fichier | Téléchargement ModelScope | Téléchargement HuggingFace | |
|
--|
-|
| | Génération de Portraits | comfyui_portrait_lora64.safetensors | Modèle Portrait | Modèle Portrait | | Transfert d'Objets | comfyui_subject_lora16.safetensors | Modèle Sujet | Modèle Sujet | | Édition Locale | comfyui_local_lora16.safetensors | Modèle Édition Locale | Modèle Édition Locale |
Modèles de Base Dépendants
| Nom du Modèle | Canal de Téléchargement | |
|
--| | FLUX.1-Fill-dev | Téléchargement HuggingFace | | Flux-Fill FP8 | Téléchargement CivitAI |
Perspectives de Développement Technique
La version actuelle présente encore des possibilités d'amélioration dans le traitement des objets complexes (précision des détails des mains 62,3%) et le support du texte chinois. L'équipe de développement révèle des plans pour lancer la fonctionnalité d'édition de trames vidéo continues au T3 2025, et publiera le modèle complet ACE++ Fully d'ici la fin de l'année.
Veuillez attendre les fichiers de flux de travail après les tests de ComfyUI Wiki pour les mises à jour de contenu Voir les Mises à Jour du Flux de Travail
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.