DeepSeek rend public Janus-Pro-7B : un modèle d'IA multimodale
DeepSeek open-source Janus-Pro-7B, un modèle d'IA multimodal pour la compréhension et la génération d'images. Apprenez à l'utiliser dans ComfyUI.
La société chinoise d'IA DeepSeek a annoncé la mise à disposition en open source de son modèle multimodale de nouvelle génération, Janus-Pro-7B, dans les premières heures d'aujourd'hui. Ce modèle surpasse DALL-E 3 d'OpenAI et Stable Diffusion 3 dans des tâches telles que la génération d'images et la réponse à des questions visuelles, et a suscité un engouement dans la communauté de l'IA grâce à son architecture "double voie de compréhension-génération" et sa solution de déploiement minimaliste. Voir l'annonce officielle
Performances : un petit modèle surpasse les géants de l'industrie

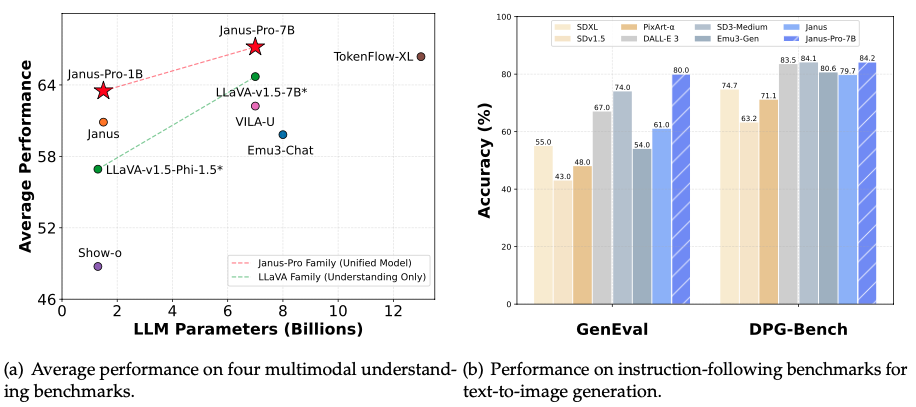
Malgré ses 7 milliards de paramètres seulement (environ 1/25e de GPT-4), Janus-Pro-7B surpasse ses concurrents dans des tests clés :
- Qualité texte-image : Atteint 80 % de précision dans le test GenEval, surpassant DALL-E 3 (67 %) et Stable Diffusion 3 (74 %)
- Compréhension d'instructions complexes : Obtient 84,19 % de précision dans le test DPG-Bench, générant avec précision des scènes complexes comme "une montagne enneigée avec un lac bleu à sa base"
- Réponse à des questions multimodales : La précision des réponses à des questions visuelles dépasse celle de GPT-4V, avec un score de 79,2 au test MMBench, proche des modèles d'analyse professionnels
Percée technique : collaboration à double voie comme "Janus"
Les modèles traditionnels utilisent le même encodeur visuel pour comprendre et générer des images, comme demander à un chef de concevoir un menu et de cuisiner en même temps. Janus-Pro-7B sépare de manière innovante le traitement visuel en deux voies indépendantes :
- Voie de compréhension : Utilise l'encodeur visuel SigLIP-L pour extraire rapidement les informations essentielles des images (par exemple, "C'est un chat orange sur un canapé")
- Voie de génération : Décompose les images en tableaux de pixels via un tokenizer VQ, dessinant progressivement les détails comme l'assemblage de blocs Lego (par exemple, texture de la fourrure, effets d'éclairage) Cette conception "diviser pour mieux régner" résout le conflit de rôles dans les modèles traditionnels et améliore la stabilité de la génération grâce à un entraînement avec un mélange de 72 millions d'images synthétiques et de données réelles.
Open Source et utilisation commerciale
- Gratuit pour un usage commercial : Publié sous licence MIT, permettant une utilisation commerciale illimitée
- Déploiement minimaliste : Propose des versions 1,5B (nécessite 16 Go de VRAM) et 7B (nécessite 24 Go de VRAM), exécutables sur des GPU standards
- Génération en un clic : Interface Gradio officielle fournie ; saisissez
generate_image(prompt="montagne enneigée au coucher du soleil", num_images=4)pour générer des images en lot
Ressources officielles :
- Dépôt GitHub : https://github.com/deepseek-ai/Janus
- Téléchargement du modèle : HuggingFace Janus-Pro-7B
Scénarios d'application : de l'art à la protection de la vie privée
- Industries créatives : Les designers saisissent du texte pour générer des prototypes d'affiches ; les développeurs de jeux construisent rapidement des ressources de scènes
- Outils éducatifs : Les enseignants utilisent le modèle pour générer des illustrations dynamiques d'éruptions volcaniques pour les cours de géographie
- Protection de la vie privée des entreprises : Les hôpitaux et les banques peuvent déployer localement, évitant de téléverser des dossiers de patients ou des données financières sur le cloud
- Diffusion culturelle : Reconnaît les monuments mondiaux (par exemple, le lac de l'Ouest à Hangzhou) et génère des images avec des symboles culturels
Ressources officielles de DeepSeek Janus**
- Dépôt de code : GitHub Janus-Pro-7B
- Téléchargement du modèle : Page du modèle sur HuggingFace
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.