NVIDIA publie LocateAnything-3B - Modèle open-source de grounding vision-langage avec décodage parallèle de boîtes
NVIDIA rend open-source LocateAnything-3B, un modèle de grounding vision-langage doté du Parallel Box Decoding (PBD) pour une localisation rapide et précise d'objets, prenant en charge la détection d'objets, le grounding d'éléments GUI, la localisation OCR et le grounding par points dans divers domaines.
Le 29 juin 2026, NVIDIA a officiellement publié LocateAnything-3B, un modèle open-source de grounding vision-langage qui permet une localisation visuelle rapide et de haute qualité à partir d'instructions en langage naturel. Le modèle introduit le Parallel Box Decoding (PBD), un nouveau paradigme de décodage qui prédit les coordonnées complètes des boîtes englobantes en une seule étape parallèle plutôt qu'un décodage autoregressif token par token, atteignant un débit jusqu'à 2,5× supérieur par rapport aux approches précédentes.
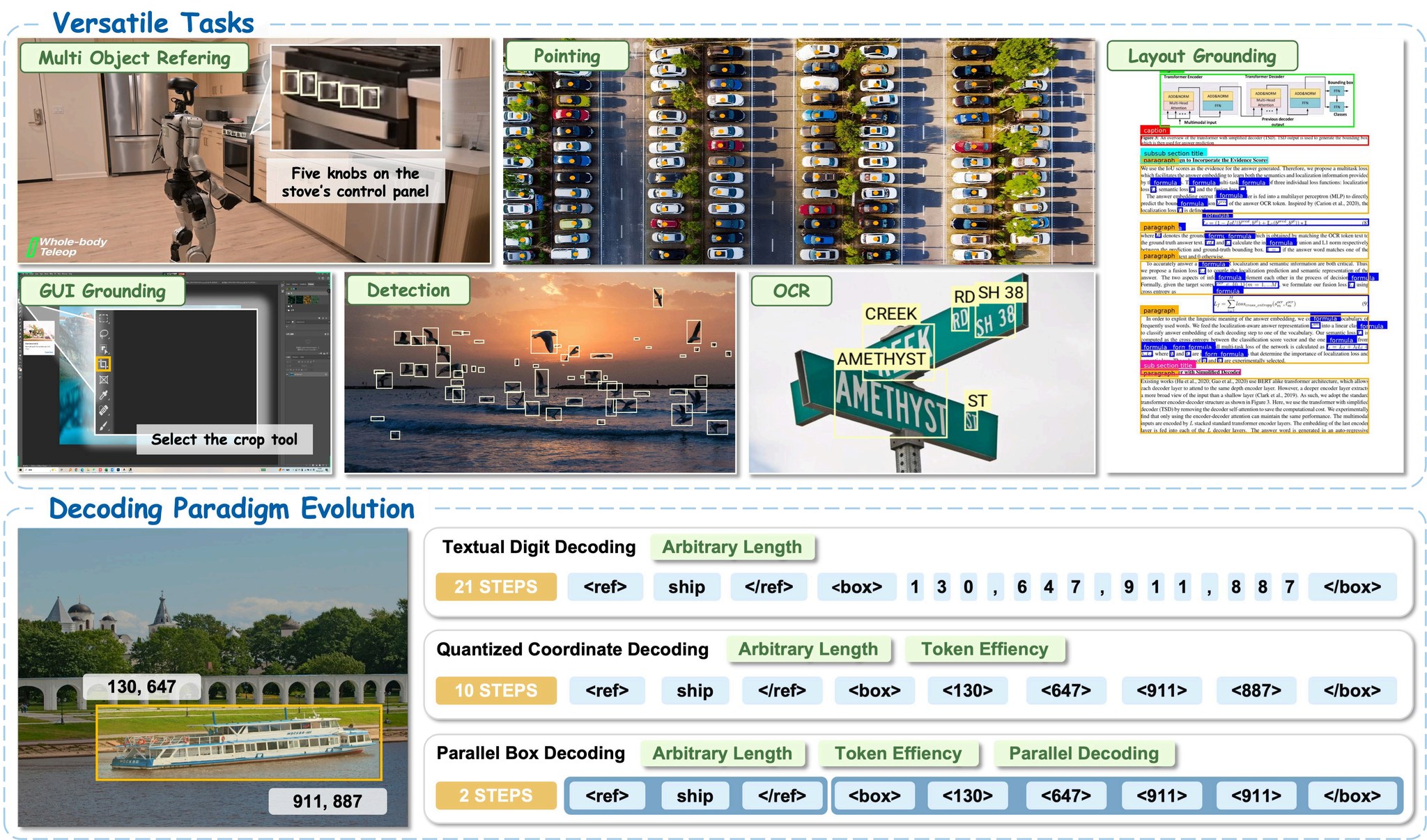 LocateAnything permet une localisation précise d'objets dans divers domaines, notamment les scènes naturelles, la robotique, l'interaction GUI et la compréhension de documents.
LocateAnything permet une localisation précise d'objets dans divers domaines, notamment les scènes naturelles, la robotique, l'interaction GUI et la compréhension de documents.
Aperçu du modèle
LocateAnything est un modèle généraliste de grounding vision-langage développé dans le cadre de la famille de modèles Eagle VLM de NVIDIA. Il prend en charge un large éventail de tâches de localisation :
- Grounding d'expressions référentes : localiser des objets décrits par du langage naturel
- Détection d'objets en ensemble ouvert : détecter des catégories d'objets courantes et à longue traîne
- Grounding d'éléments GUI : localiser des éléments d'interface pour les systèmes agentiques
- Grounding de mise en page de documents : OCR et localisation de texte
- Localisation par points : raisonnement spatial fin via pointage
Le modèle a été intégré dans les gammes de produits Nemotron et Cosmos de NVIDIA, alimentant les fonctionnalités d'utilisation informatique et de grounding visuel.
Innovation clé : Parallel Box Decoding (PBD)
Les modèles traditionnels de grounding visuel génèrent les coordonnées des boîtes englobantes de manière autoregressive, token par token. LocateAnything introduit le Parallel Box Decoding :
- Prédit les boîtes englobantes complètes (
x1, y1, x2, y2) et les points dans des unités structurées parallèles - Utilise un cadre de prédiction multi-tokens par blocs
- Atteint un débit 2,5× supérieur sans sacrifier la cohérence géométrique
- Prend en charge trois modes d'inférence :
- Mode rapide : décodage parallèle pour une vitesse maximale
- Mode lent : décodage autoregressif pour une précision maximale
- Mode hybride : par défaut ; décodage parallèle avec repli autoregressif en cas d'irrégularités de format
Architecture technique
| Composant | Détails |
|---|---|
| Architecture | VLM basé sur Transformer |
| Encodeur visuel | MoonViT (résolution native, jusqu'à 2,5K) |
| Modèle de langage | Qwen2.5-3B-Instruct |
| Projecteur multimodal | Projecteur MLP |
| Paramètres totaux | 3B |
| Résolution d'image max. | 2,5K (production), jusqu'à 4K avec inférence par lots |
| Longueur de séquence max. | 25 600 tokens (entraînement), 8 192 tokens de génération (inférence) |
| Format de sortie | Basé sur les blocs : blocs sémantiques, boîte, négatif et fin |
Données d'entraînement
- 12 millions d'images uniques, plus de 138 millions de requêtes, 785 millions de boîtes englobantes
- Multi-domaines : scènes naturelles, robotique, conduite, GUI, documents
- Sources de données hybrides : annotations humaines, open-source, synthétiques assistées par modèle
Performances
LocateAnything démontre des performances solides sur plusieurs benchmarks de grounding, notamment COCO/LVIS pour la détection en ensemble ouvert, ScreenSpot-Pro pour le grounding GUI, et divers benchmarks de compréhension de mise en page de documents.
Efficacité d'inférence
Avec le backend d'attention la_flash et l'inférence hybride par lots :
| Backend | Temps (sonde 4K) | Mémoire maximale |
|---|---|---|
| SDPA (masques denses) | 8,26 s | 35,12 Go |
| la_flash (FlashAttention) | 8,03 s | 11,71 Go |
Open Source et disponibilité
LocateAnything-3B est publié sous la Licence NVIDIA pour une utilisation non commerciale de recherche et développement :
- Modèle HuggingFace : nvidia/LocateAnything-3B
- Code GitHub : NVlabs/Eagle/Embodied
- Démo en ligne : HuggingFace Spaces
- Rapport technique : arXiv:2605.27365
- Page du projet : NVIDIA Research
Configuration matérielle requise
Optimisé pour les GPU NVIDIA (Ampere, Blackwell, Hopper, Lovelace) avec précision BF16 et cache KV. L'inférence par lots via le backend la_flash réduit la mémoire maximale de 35 Go à environ 12 Go sur A100.
Liens connexes
- Dépôt GitHub : https://github.com/NVlabs/Eagle/tree/main/Embodied
- Modèle HuggingFace : https://huggingface.co/nvidia/LocateAnything-3B
- Démo en ligne : https://huggingface.co/spaces/nvidia/LocateAnything
- Rapport technique : https://arxiv.org/abs/2605.27365